")

The shift to cloud native creates a new need for data management
With the move to cloud native applications and microservices architecture, the volume of data generated has exploded. By some estimations, cloud native environments emit 10x and 100x more data than traditional VM-based environments.
Yet, logs, metrics, traces, and event data (collectively known as telemetry or observability data) all contain information that teams need to monitor performance, troubleshoot issues, and reduce mean time to remediate (MTTR). The ever-increasing volume of data makes it harder for teams to locate actionable insights amongst all the noise and increases the costs of storing and analyzing the data.
Today, many companies leverage observability and Security Information and Event Management (SIEM) platforms to collect, store, and analyze telemetry data. However, with the increase in data volume, data sources, and data destinations, companies need more comprehensive tools to collect, transform, and route telemetry data before sending it to these backend systems.
Enter the telemetry pipeline. Telemetry pipelines enable organizations to receive data from multiple sources, enrich, transform, redact, and reduce it before routing it to its intended destinations for storage and analysis. The result is that organizations are able to control their data from collection to backend destination, reducing the complexity of managing multiple pipelines, reducing the volume of data sent to backend systems, and decreasing backend costs.
This post provides an introduction to the telemetry pipeline. It provides a quick overview of what telemetry pipelines do and how they differ from the observability and SIEM platforms with which they integrate. Along the way, we offer some advice about why you may — or may not — need a telemetry pipeline solution.
What observability and SIEM platforms do
To better understand what a telemetry pipeline does, let’s compare it to what observability and SIEM platforms do. In an admitted oversimplification, observability platforms and SIEMs:
- collect data
- route data
- store data
- analyze data
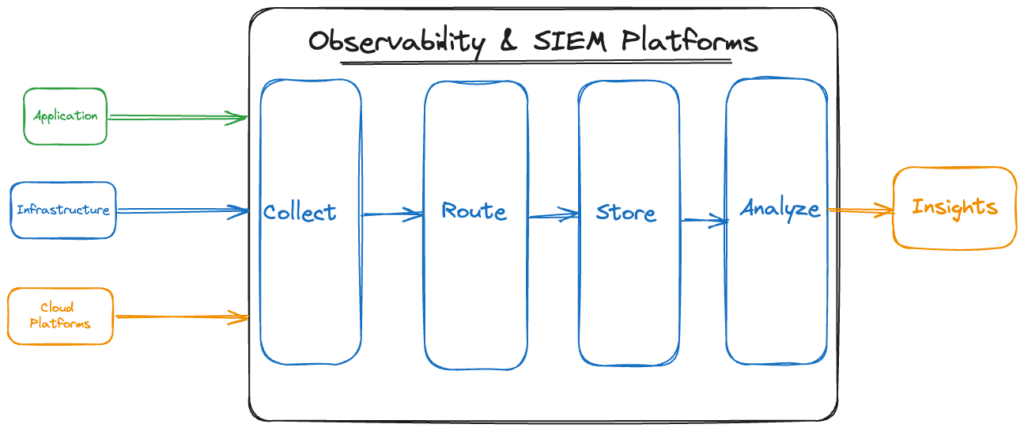
Observability platforms give developers and infrastructure teams visibility into their software applications and environments and provide insight into the state of their applications and infrastructure. SIEM platforms, on the other hand, are concerned with security information and events. Security teams use SIEM platforms to recognize and address potential security threats and vulnerabilities before they disrupt business. Both platforms may use some of the same data, especially logs, but they examine it through different lenses.
Collector agents: the worker bees of telemetry data
The collection of data is typically handled by an agent, a small application running on or adjacent to the data source that gathers logs, metrics, and/or traces and delivers them to the platform for storage. Collector agents are the worker bees of observability and SIEM platforms, tirelessly gathering data and delivering it back to the hive (platform) for the good of the larger organization. These agents are often proprietary, and can only be used to route data exclusively to the vendor’s platform. Some platforms may allow the use of open source agents like Fluent Bit or the OTel collector instead of proprietary agents. However, be cautious; in some cases, they actually require forked versions of these open source collectors that have been engineered to work specifically with their platform.
Large organizations may require hundreds or even thousands of collectors, spread out across Kubernetes pods, VMs, and other infrastructure. When platforms require vendor-specific agents they further tighten the screws of vendor lock-in — to switch platforms, organizations must not only face the pain of the platform change itself, but must also contend with uninstalling all of their collector agents, and installing and configuring new ones that work with the new platform.
eBook: The Buyer’s Guide to Telemetry Pipelines
Build a smarter telemetry pipeline. Download The Buyer’s Guide to Telemetry Pipelines
What telemetry pipelines do
Telemetry pipelines allow organizations to control their data from collection to backend destination, alleviating the complexity of managing multiple pipelines, reducing the volume of data being sent to observability and SIEM platforms, and decreasing backend costs.
Telemetry pipelines focus on these tasks
- collecting data from multiple sources
- transforming data to make it compatible with required endpoints
- processing data to apply business logic
- enriching data to provide context
- reducing data reduce noise and control costs
- routing data to multiple sources
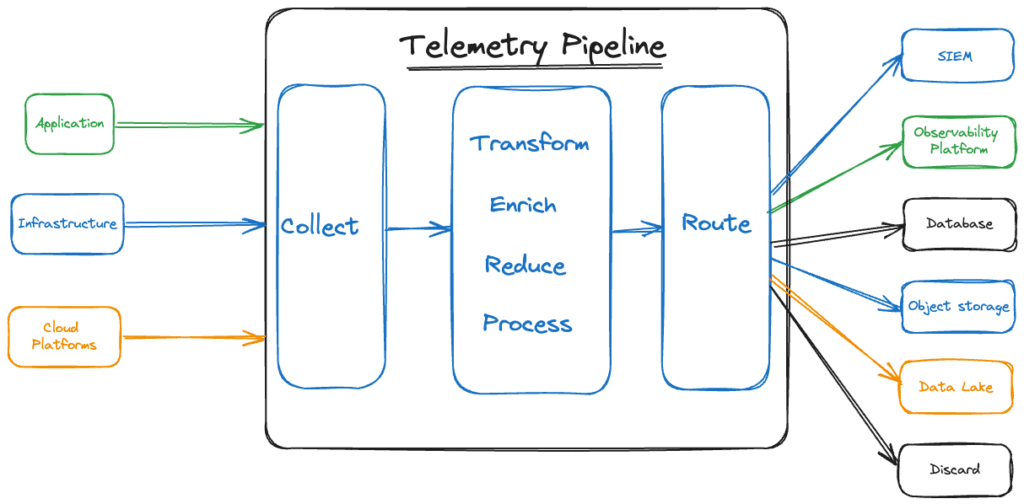
While there is some overlap between the tasks performed by telemetry pipelines and observability and SIEM platforms (i.e., collection and routing), telemetry pipelines are typically unconcerned with insights derived from the data. Their focus is on collecting, routing, and processing data before it is stored and analyzed.
Telemetry pipelines bring value in four primary ways:
- Simplifying infrastructure. Without a telemetry pipeline organizations are forced to manage tens if not hundreds of individual data pipelines to connect each source to each destination.
- The ability to process and manipulate data (i.e., transform, enrich, reduce) as the data moves through the pipeline.
- Expanding the possibilities for where you can send your data, allowing you to route it to multiple destinations as needed.
- Breaking free of vendor-specific collection agents, typically by accepting data from multiple agents or by supporting open standards.
Value through simplifying infrastructure
Without a dedicated telemetry pipeline solution, the process of moving data from multiple sources to multiple destinations can become quite complex. It’s not unusual to see architectures that resemble something like this:
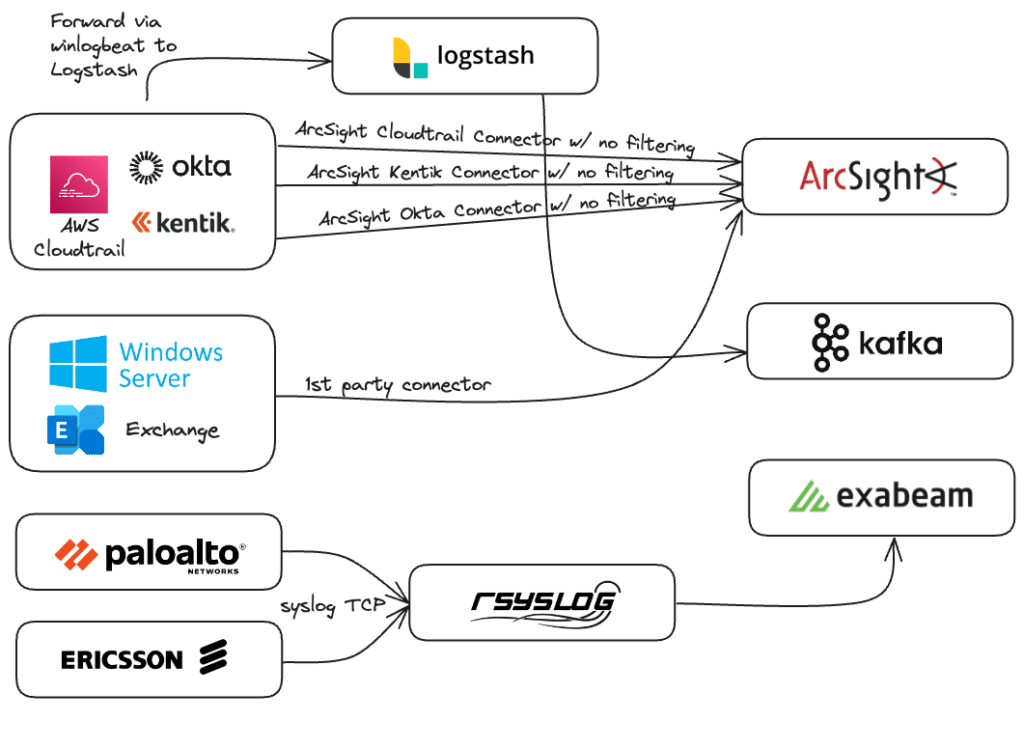
A dedicated telemetry pipeline solution can tame the tangle. Vendor-neutral agents replace multiple vendor-specific agents. Multiple intermediaries are eliminated as data flows through a single solution for routing to multiple destinations.

A simplified architecture is easier to maintain, and built-in integrations make onboarding new sources or destinations much faster. As a result, developers are freed up to focus on writing the code and building the applications that will drive their businesses rather than writing custom connectors and transformations.
Value through data processing
Transforming and processing data in the pipeline reduces the stress on the endpoint platform. If a platform stores log files as JSON, for example, the telemetry pipeline can handle the intensive process of converting raw log files into structured data ready for storage and analysis.
Because telemetry pipelines sit between the data sources and the data destinations, they can access information about sources that would typically be unavailable further downstream. This is particularly true for ephemeral containerized environments. The pipeline application can then enrich the telemetry data with this additional context before routing it to its final destination where teams can then use it to troubleshoot issues.
The pipeline’s proximity to the data sources makes it ideal for removing or redacting sensitive data that should not be made available to downstream systems. This is an essential step for some compliance regulations.
Telemetry pipelines can also significantly reduce the amount of data delivered to platform endpoints. They do so by identifying and dropping duplicate records, and, more significantly, by applying rules to filter out unnecessary data. It’s a trivial matter, for instance, to eliminate all debug-level logs if desired. Judicial filtering rules eliminate noisy data, making it easier for observability and security teams to derive true insights from their platforms. Since many platforms charge based on the amount of data stored and processed, reducing the data flow can result in significant cost savings as well.

Value through multi-routing
With their ability to route data to multiple destinations, telemetry pipelines significantly reduce the complexity of moving data to where it is needed. Telemetry pipelines help break down data silos by making data available everywhere it is needed. They help with compliance by being able to route data to inexpensive long-term storage for retention and auditing while also routing a subset to systems for active analysis. Organizations that have yet to settle on a single platform for different types of telemetry data can eliminate the need for multiple agents installed on each source.
Value through eliminating vendor lock-in
Vendors know that the time, effort, and expense associated with replacing their platforms with a competitor give them an advantage when it comes to contract renewals. Dedicated telemetry pipelines can shift the balance of power, giving organizations more control over their data. They can eliminate the necessity of swapping out thousands of collector agents. Business logic applied to data in flight does not need to be recreated. Changing destinations becomes a configuration change. The time, effort, and expense of ripping and replacing drops dramatically, and renewal negotiations can become more equitable.
Of course, no major system migration is without its pain points. However, having a telemetry pipeline can significantly reduce them. In fact, organizations that are unhappy with their platforms sometimes integrate a telemetry pipeline as a preliminary step to migrating to a better platform.
When do you need a telemetry pipeline?
Whether your organization would benefit from a dedicated telemetry pipeline solution depends on your specific needs. If you are still reading this far, chances are good that you may be ready.
In general, organizations begin exploring telemetry pipeline solutions when they experience one or more of the following pain points:
- The complexity of their observability/SIEM program requires too many resources to manage and decreased efficiency. This could manifest itself as delays in onboarding new data sources or destinations, engineers pulled from other projects to help manage or create a pipeline, or issues with scaling as data volume increases.
- They must send data to multiple destinations and can’t easily do so.
- They need to transform their data or apply business logic based on its content (e.g., enrich it with metadata, redact/remove sensitive data before storage, apply structure to unstructured data, route data differently depending on context).
- Their data is too “noisy,” making it difficult to identify actionable insights and increasing time to remediate.
- They need to control costs by reducing the volume of data sent to their backends.
If any of the above sound family, a dedicated telemetry pipeline solution can help.
Getting Started with Fluent Bit and OSS Telemetry Pipelines
Read the Book that Helps You Navigate the Complexities of Open Source Telemetry Pipelines with Fluent Bit


