Cloud native gives you the power to innovate faster, improve efficiency and gain a competitive edge. But with that power comes significant complexity that can impact your ability to rapidly address customer-facing problems.
With Chronosphere, you can harness the power of cloud native and turn it into a business advantage.
The Chronosphere Advantage
Customer expectations are unattainably high, with greater stakes than ever before. You need a solution that gives you real-time insight into every layer of your stack to ensure you’re meeting performance and availability objectives, without breaking the bank. Get it wrong and the results can be catastrophic, leading to increased costs, lost revenue and customer churn, and engineering toil instead of innovation.
Chronosphere is the leading cloud native observability platform that is purpose built for the speed, scale, and complexity of cloud native infrastructure and application helps you bridge that gap.
Return on Investment,
according to Forrester Research
Benefits present value,
according to Forrester Research
Payback period,
according to Forrester Research
Solutions by Layer
To effectively operate in today’s cloud native world, you need a solution that can connect the dots throughout the stack, from the infrastructure to the application to the business. Previously, tools took a siloed approach to each of these layers, but today you need to see real-time performance and response data across all layers of the stack in order to rapidly find and fix issues.
Infrastructure observability
Infrastructure metrics are the backbone of your observability implementation. This is especially true in a cloud native infrastructure environment. With an efficient cloud infrastructure monitoring solution that was purpose-built to reliably handle the scale of cloud native, you will know about issues before your customers do.
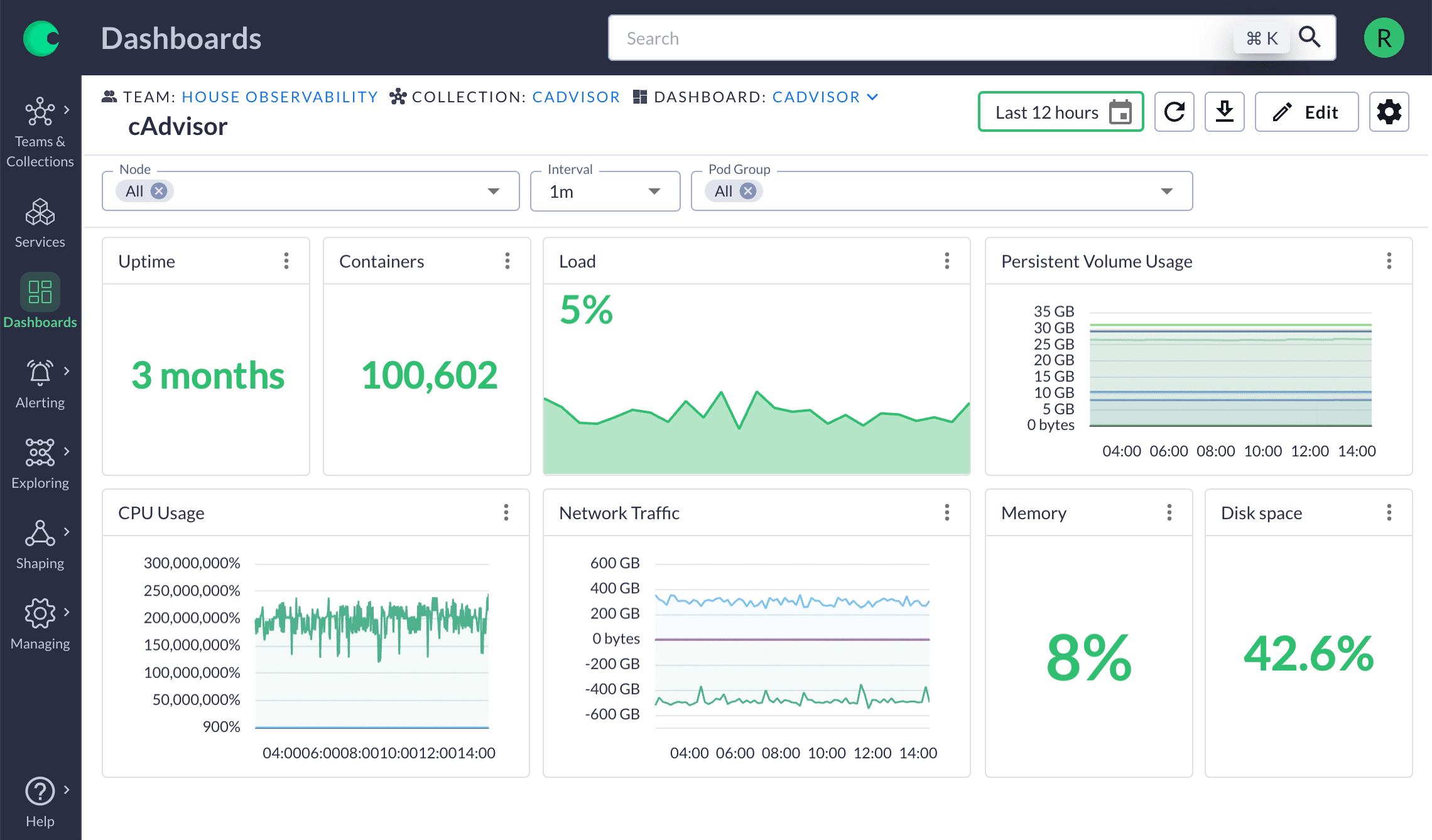
Chronosphere ingests a variety of open source infrastructure metrics formats from Prometheus to Graphite/StatsD and ships with out of the box dashboards like cAdvisor that give you instant insight into your Kubernetes clusters making Kubernetes monitoring easy.
With Prometheus, you can export infrastructure metrics from virtually any server, database, or service mesh. Monitoring infrastructure is a foundational to your observability strategy.
Prometheus exporters and integrations
PromQL compatible
Application observability
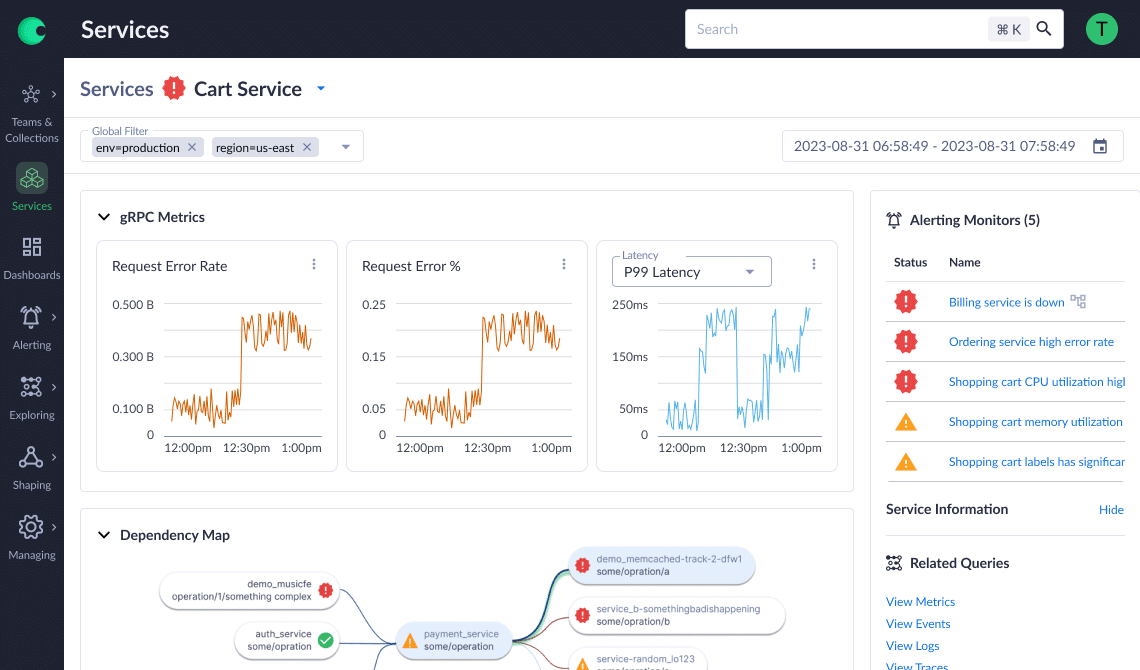
Application performance monitoring (APM,) or the task of troubleshooting application errors or performance issues, is no easy feat in a distributed microservices environment. With Chronosphere, engineers of any experience level can understand the root cause of issues via the insights provided by the automated analysis of the underlying Observability data.
Harnessing the power of distributed tracing via OpenTelemetry, your tangled mess of microservices goes from unintelligible to understandable. The results? Fewer incidents, faster resolution, happier customers and developers thanks to the power of cloud native application monitoring.
Reduction in incidents
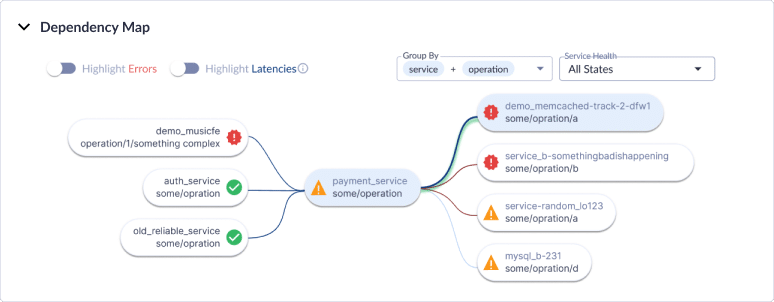
Map service dependencies
Business observability
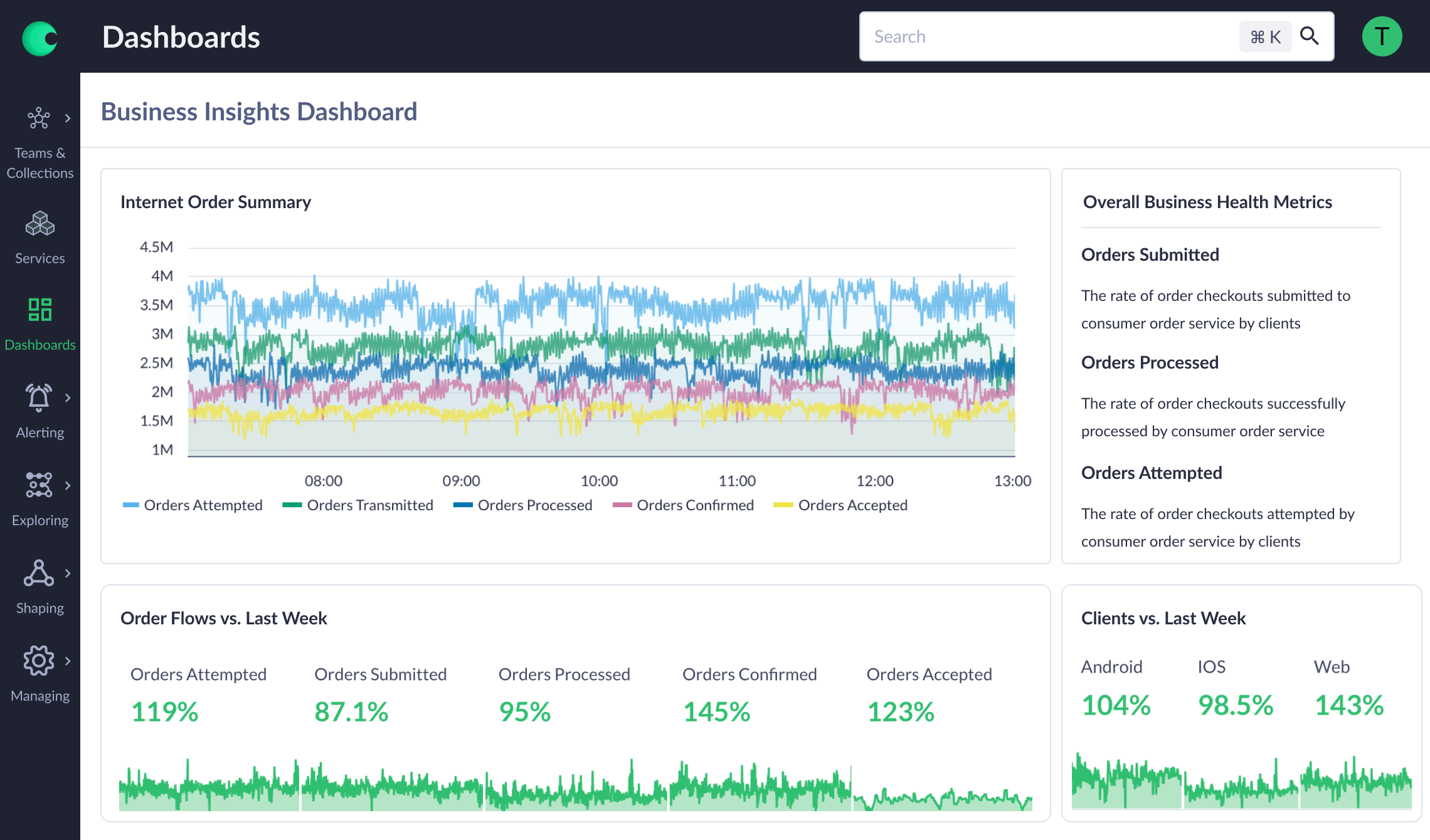
When your business moves at the speed of cloud, you can’t wait hours or days to understand business impact. With Chronosphere’s millisecond ingest and one second alert intervals, you can react to business metrics like revenue flow and customer engagement in seconds.
With a single solution that can connect infrastructure errors through to application performance all the way up to business impacts, you always have a 360 degree view of your business performance.
Ingest latency
Alert intervals
Solutions by Use Case
In today’s high complexity cloud native world, you need to reduce downtime, remediate issues, and eliminate problems before you impact customers. You want a solution that meets you where you are and can grow with you without costing an arm and a leg.
Chronosphere’s cloud native observability platform gives you the ability to reign in costs and resolve incidents faster with a reliable and scalable SaaS solution.
Control Observability Costs
Cloud native environments produce massive amounts of telemetry data. Developers need this data to effectively operate and troubleshoot systems, but it quickly leads to observability costs spiraling out of control.
With Chronosphere, you still collect all the same data, but it’s aggregated and transformed into actionable insight that is usable for developers, while also being highly cost efficient. The result is greater predictability, increased accountability, and significant cost savings.
average data reduction with Chronosphere
Of companies are concerned about their observability data growth
Accelerate MTTx
When customer-facing issues arise, your developers need the best tools to solve these issues, fast. Chronosphere rapidly orients developers to the problem at hand with context-rich alerts and seamless linking of data types for faster time to triage. With a solution that is accessible for all levels of developers, you will no longer have your most senior resources pulled into every incident response.
The results? When you can scale reliably and meet customer demand, you’ll see increased revenue and less customer churn.

Boost Observability Uptime and Performance
When your observability solution is unreliable, the entire organization suffers. Developers can’t ship code, or worse, fly blind during an outage. They spend longer on troubleshooting, which means they are slower to deliver new features, which in turn frustrates customers and puts revenue at risk.
With Chronosphere, you gain an observability platform that is reliable, scalable, and performant, so engineers spend less time in the weeds and more time innovating
less time troubleshooting
developer hours saved per year by Affirm
historically delivered uptime

Scale Open Source Tools
While many organizations begin their cloud native observability journey with open source tools like Prometheus or Jaeger, they quickly run into major hurdles. The two big challenges that companies face when running their own open source observability in-house is the significant management overhead and tooling that is unreliable and slow.
With Chronosphere, you get the best of both worlds: a fully open source compatible solution that relieves the management overview and delivers best in class availability and performance. Win-win.


It's not just Chronosphere serving data up to us. They partner with us, they've had these problems before, and it's a large collaborative effort between us and them.


"The long-term impact of switching to Chronosphere is freeing up headspace to tackle the hard problems and deliver business value and a better experience for our customers."

“Chronosphere allowed us to not only deal with the huge amount of data we were producing, but also to be able to shape that data on ingest and pick and choose the data we knew would be important. This means we could reduce our costs by over 85%”






