



Before the acceleration of modern DevOps practices, software engineers primarily wrote code. Now the job is so much more—from getting apps production-ready & iterating quickly to scale new services to architecting system compatibility and ensuring compliance & reliability—and that’s elevated the need for exceptional instrumentation. But what does great instrumentation involve and where should you begin?
I tackle the answer to this question in a new book on observability I co-authored along with Chronosphere’s co-founder and CEO, Martin Mao, and cloud native expert, Kenichi Shibata—O’Reilly’s Cloud Native Monitoring: Practical Challenges and Solutions for Modern Architecture.
Instrumentation is the process of building a great observability function, which first and foremost includes standardized metrics and dashboards tied into business context. With exceptional instrumentation that aligns site reliability with business goals, software engineers and site reliability engineers (SREs) can further give their organization a competitive advantage. In chapter 5, we share the tips and tricks to building a great instrumentation and metrics function, which I have excerpted and paraphrased below.
7 ways to build great instrumentation and metrics functions
The trick to great instrumentation is building a great metrics function that helps your organization find the right balance between too much and not enough information. Our book explains seven ways to achieve that goal.
1) Start with out-of-the-box standard instrumentation and dashboarding
SRE teams and software engineers using open source tools can enable standardized metrics and dashboards right out of the box. Let them get started right away.
They can, for example:
- Give any HTTP-based or RPC service an automatically provisioned dashboard that includes infrastructure and compute metrics if those metrics are collected with Prometheus from Kubernetes/Envoy/nginx/service mesh
- Use a specific API, then build a dashboard for any team that implements the API for organization-specific metrics (i.e., sales data).
- Create a Request Rate, Request Error, Request Duration (a.k.a. RED) metrics dashboard for software engineers to observe and monitor customized, pre‐built apps.
2) Enlist internal software engineers and SRE/observability teams to deliver standard dashboards
Internal software engineers or SRE/observability teams are better choices than any vendor to build and create standardized dashboards because they know your business context best. That makes them best positioned to achieve desired business outcomes.
How that works in practice is that they’ll know how to:
- Create RPC (Remote Procedure Calls) dashboards and alerts if your organization relies heavily on RPCs.
- Collect key metrics using appropriate middleware (e.g., Java or Go Prometheus gRPC middleware libraries or metrics exposed by an RPC proxy).
- Create dashboards and alerts that monitor key infrastructure like Kafka topics for each application if your main event bus management system is Kafka.
3) Add business context to standardized metrics
With standardized metrics and dashboards in place, you can begin to add your business context. These three examples illustrate how
- Traffic patterns – Enrich your metrics by adding new labels such as tenant_id and tenant_name to the standard out-of-the-box instrumentation. You then can use that label to understand how traffic is being served between different tenants/clients. If you find one organization creating more requests to your services, you can scale the hosting servers and notify the customer. For example, see if tenant_name ACMECorp is creating more requests to your services, then scale the servers hosting ACMECorp and possibly send an email to ACME Corp about the increased usage.
- Alert routing customization – Troubleshoot faster by adding the names of the app and alert-owning team so alerts are always routed to the right people. Also add dependent applications so alerts go to teams downstream from that app, too (using config as code or queries with label join on HTTP/RPC metrics). This allows you to detect a cascading failure and pinpoint where it starts.
- Tiering applications – Prevent the downtime of systems that should never stop running by adding labels with tiers to differentiate them, then route alerts differently based on tier. For example, tier 1 alerts would go not only to technical staff but also to other teams, spurring greater numbers of people into action to stay ahead of potential issues.
4) Create SLOs from standardized instrumentation
Derived from key metrics, service levels help you align site reliability with your business goals. These three concepts, defined by Stavros Foteinopoulos of Mattermost, are key to understanding service levels:
- Service level indicators (SLIs) — A carefully defined quantitative measure of some aspect of the level of service provided (in short, a metric).
- Service level objectives (SLOs) – A target value or range of values for a service level that is measured by an SLI, or what you want your metric’s value(s) to be.
- Service level agreements (SLAs) – Contracts that promise users specific values for their SLOs (such as a certain availability percentage) and lay out the consequences if you don’t meet those targets (SLOs).
Here’s an example of those three concepts in practice:
If fictitious Feline Company builds an API that provides cat memes for app developers to use, its SLI is the percentage of time that API is available to all downstream external customers. If its SLO is 99% availability, it’s promising customers no more than 3.65 days of downtime per year. This is measured by an error rate formula. If downtime errors exceed the limit specified in the SLO, the SLA states the company agrees to donate $1 to an animal shelter per additional minute of downtime.
If your company’s SLI is availability, you have likely already instrumented a set of standardized metrics, like the Prometheus RED metrics. In that case, you can use those standardized metrics to build a dashboard, which will make it fairly straightforward to create realistic SLOs based on performance. But you must also standardize what each SLI means across the organization. For example, what is 99% availability? The rule of thumb here is consistency across an organization.
5) Be sure to monitor the monitor
It’s important to know two things about monitoring: who monitors the monitoring system? What happens when it goes down?
These three rules can help ensure reliability:
- Rule #1 – Don’t run your monitoring in the same region where you run your infrastructure to avoid a monitoring accessibility outage during infrastructure degradations.
- Rule #2 – Use a different cloud provider from the one running your production workloads. This ensures you will still have accessibility to your monitoring system even if entire segments of cloud providers or SaaS services go down.
- Rule #3 – Use an external probe on the internet (for publicly facing applications) or an internal probe in a different region but within your network to provide real-time synthetic monitoring. This means you can see what your end users see from different origins.
6) Establish write and read limits
Metric cardinality is fundamentally multiplicative. One engineer can write a single query that can read metrics with a cardinality in the order of 10s to 100s of million time series. Because you cannot safely guarantee a system will not be overloaded answering this query, it’s best practice to build a detection system to understand if one of your queries or writes will cause an outage.
Read and write matters for developers and users:
- For write use cases – Show your developers the cost of each metric write they add by allowing them to monitor their publishing rate. With this view, they can see their usage relative to other applications and teams, and know when they are using more than their fair share of resources.
- For read use cases – Permit users to only query for the data they need quickly and fairly share query resources when querying larger volumes of data. Also make sure the cardinality matches their appropriate use (using automation or otherwise) because queries frequently use the same set of storage resources that 10s of thousands of real time alerts share. (Read What is high cardinality for a deep explanation of this complex topic.)
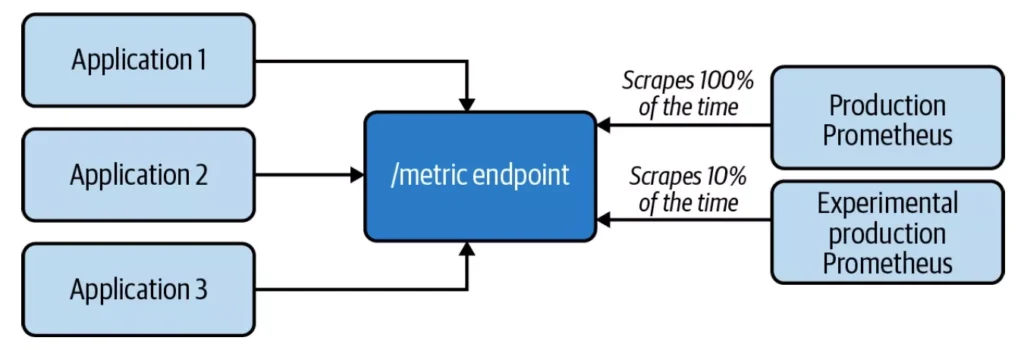
7) Establish a safe way to experiment and iterate to drive innovation
If you are highly dependent on today’s monitoring system and can be concerned about making major changes to it, you’re creating a different set of challenges. You have no way to experiment and iterate. You’re also prevented from learning new technologies and tools without breaking your current system observability technology stack.
You can avoid this scenario by making it safe to create a new set (or subset) of monitoring data in another observability system. Try to get 10% of all production observability data onto the new system without your developers doing anything more. Different observability systems let your SREs safely experiment—without a developer needing to change or redeploy code—with things such as:
- New relabel rules
- Upgrading your Prometheus version
- Creating a new aggregation across different types of metrics
- Ingesting a new set of data from a completely different type of tech stack
- Measuring the daily metric size
- Iterating safely on existing tasks, like adding new cardinality to existing metrics.
- Destroying/recreating observability stacks to teach new SREs how systems work
Cloud native observability boosts instrumentation success
Modern observability platforms such as Chronosphere empower you and your team to learn more about your systems and applications at a level of granularity that’s been so difficult to establish at scale historically. Join the organizations across industries choosing observability platforms to build a great observability function that puts you in control of your telemetry and increase business confidence and effectiveness Download the Cloud Native Monitoring Report from O’Reilly to learn more.


