Without observability it’s just code — O11y guide part 7
")
Setting a strategy and focusing on the three phases of observability will help you turn your code into actionable insights.

On: Mar 7, 2024
Eric is Chronosphere’s Director of Technical Marketing and Evangelism. He’s renowned in the development community as a speaker, lecturer, author and baseball expert. His current role allows him to help the world understand the challenges they are facing with cloud native observability. He brings a unique perspective to the stage with a professional life dedicated to sharing his deep expertise of open source technologies, organizations, and is a CNCF Ambassador.
Welcome to another chapter in the ongoing series I started covering my journey into the world of cloud native observability. If you missed any of the previous articles, head on back to the introduction for a quick update.
After laying out the groundwork for this series in the initial article, I spent time sharing who the observability players are, looked at the ongoing discussion around monitoring pillars versus phases, and shared thoughts on architectural level choices being made, and shared the open standards available within the open source landscape. I continued onwards with a few of the architectural challenges you might encounter when older monolithic applications and monitoring tools are still part of an organization’s infrastructure landscape.
Being a developer from my early days in IT, it’s been very interesting to explore the complexities of cloud native o11y. Monitoring applications goes way beyond just writing and deploying code, especially in the cloud native world. One thing remains the same, maintaining your organization’s architecture always requires that you understand that without observability, it’s just code you are deploying.
Let’s look at what makes cloud native observability so crucial to your organization’s success.
The phrase Without Observability It’s Just Code originated back 10 years ago when I first designed a t-shirt for some event with the theme being around DevOps with the phrase Without Ops, It’s Just Code. Today it’s not hard to see the transition to cloud native observability has become essential for many organizations as they explore digital transformation paths to modernizing their architectures.
Cloud native complexity
Initially when developers and operations teams were moving into the cloud, they were confronted with infrastructure as a service (IaaS) processes and often they were virtual machine (VM) based environments. These led to environments they could both understand and monitor without too much drama. This was due to the one-to-one relationship often found between the VM-based infrastructure, hosting a monolithic application, that delivered to the business a product or service that their customers were able to use.
As the evolution to cloud native became a reality, these same developers and operations teams were exposed to auto-scaling, descriptive environments where containers and microservices became the new normal. The complexity skyrocketed overnight with relationships becoming many-to-many as infrastructure became a sea of containers running on container platforms, applications split out from single monoliths into multiple microservices, and businesses are now presenting use cases, clients, and geo-located interactions with the underlying microservices.
This complexity brings more data with it, both application generated data as customers interact and monitoring data. This growth in data means that costs are higher to operate in these environments, especially when you are applying the same observability technologies to this new cloud native environment.
What happens when your organization is successful in a cloud native environment and all of the above issues are applied at massive scale?
Cloud native at scale
When developers and operations teams are working in a cloud native environment at scale, other problems arise. The time with which teams must act and react is drastically shortened, with delivery of code being done in smaller increments and at a much faster pace. With hundreds or thousands of microservices being developed, updated, and deployed multiple times a day or even inside an hour, the processes that brings together the DevOps culture becomes a necessity.
Along with the processes comes a flood of new data, from applications, microservices, containers, observability, and other aspects of the cloud native environment. This also results in tooling sprawl, where many new tools enter the domains of the DevOps teams. All of this increases the cognitive overload and stress for these teams.
If you look around the internet searching for how much time developers are actually spending on the job they signed up for, coding and building new things, is shocking. Here are just a few samples of the results you might find:
- Developers spending 32% of time writing or improving new code.
- Eighty-three precent of developers are burning out, 20% of engineers suffering from burnout attributed the cause to “unreliable software.”
In the following diagram you can see the, maybe a bit optimistic, split on how developers in DevOps teams are buried in everything but the new development for organizations that hired them.
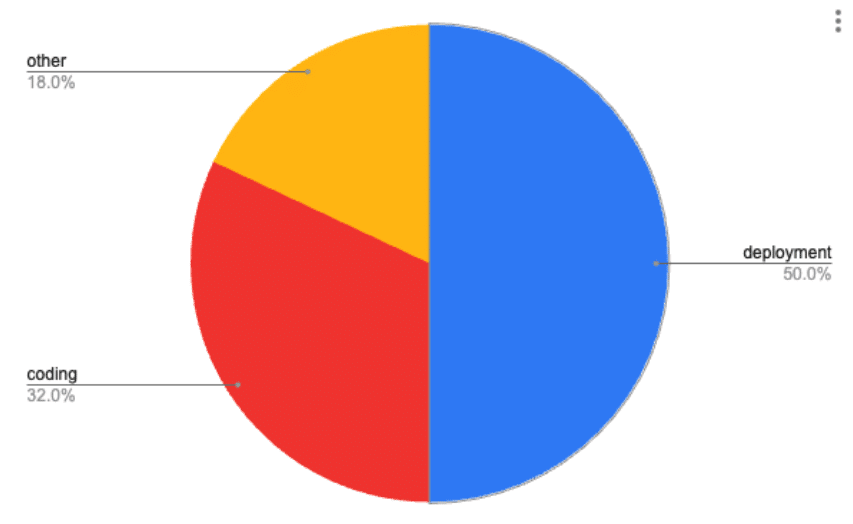
Are you wondering how organizations are dealing with these challenges?
Facing the challenges
In a recent article I read, The growth of observability data is out of control, two important statements were made that describe the situation and how organizations are facing these challenges.
“It’s remarkable how common this situation is, where an organization is paying more for their observability data (typically metrics, logs, traces, and sometimes events), than they do for their production infrastructure.”
The research backs up this statement, when “…69% of companies are concerned with the rate of growth of their observability data.”
Furthermore, when a simple Hello World application is deployed on a four node cloud cluster and basic metrics are collected, the results were shocking. Thirty days of data was collected and it ended up generating +450 GB of data, that’s almost half a terabyte of data you have to store, query, and pay for. Can you imagine if you run hundreds of thousands of applications?
Let’s be honest, the cost would not be the problem if the outcomes were better. If you customers were happy, if you can fix issues quickly, or if you are able to retain your DevOps resources without burning them out on call. Short of collecting less data on purpose, the problem will remain as your data increases.
So what does observability look like that elevates your code beyond just code?
O11y happiness
The key to understanding observability happiness is to no longer approach this as solvable with the mantra of metrics, logs, and tracing. Putting a solid strategy in place, with a business outcome focus will lay the foundations for a successful cloud native existence. Focus on the three phases of observability; know, triage, and understand.
You need the ability to approach, for your on-call engineers, cloud native observability through the three phases:
- First, you need to know about issues, as quickly as possible. You need to know what happened and when and what systems were impacted. Ideally, finding out BEFORE a customer is impacted.
- Then you need to triage and begin understanding the impact and who can help. From there you can determine which teams need to get involved and what priority level it is.
- Lastly, you need to be able to understand the root cause of the problem.
A large part of this approach is being able to get control of the data being generated, collected, and stored in your cloud native environments. Having the ability to gain insights into how much data is actually useful and what data is not being used at all. Imagine finding out that you are ingesting +130k data points per second and paying for that storage, while you find out later that with 180 data points you are drawing the same graphs on your dashboard that is observing this system?
This all leads to better outcomes, from cost savings on data storage, to lower cognitive loads on your teams. Making sure you are aware of the complexities and challenges of cloud native environments gives you the chance to tackle these challenges before they become obstacles to your organizations cloud native success. Take the time to understand your observability needs, because in a modern cloud native world, without observability, all you are doing is generating a lot of code.
Check out the other articles in this series:
Part 6: Getting started with Perses
Part 5: Monoliths into the cloud native world
Part 4: Keeping your cloud native observability options open
Part 3: Cloud native observability needs phases
Part 2: Who are the cloud native observability players?
Part 1: Your first steps in cloud native observability


