

Introduction
In this blog you will learn about:
- What makes multi-line logs challenging
- How to configure a multi-line parser in Fluent Bit
- Choosing the right parsing approach
Logs are essential for monitoring and debugging applications, but not all logs are created equal. While most logs follow a simple line-by-line format, others span multiple lines to improve readability. However, when mixed with other logs, these multi-line log entries can become challenging to parse and analyze. Important details can get lost in the noise without proper handling, making troubleshooting more time-consuming.
To address this challenge, Fluent Bit allows the consolidation of multi-line logs into a single structured entry. In this post, we’ll explore the complexities of multi-line logging, why it matters, and how to configure Fluent Bit to capture and manage these logs.
Challenges with multi-line logs
Why managing multi-line logs is challenging
Unlike standard single-line log entries, multi-line logs such as stack traces span multiple lines, making them harder to process and analyze.
Many log processors treat each line separately, making debugging difficult, which causes critical information to become fragmented. This affects readability and makes troubleshooting harder since logs from various sources can mix, making it difficult to trace the full context of an error.
This fragmentation also makes it harder to filter, search, and correlate logs in monitoring tools. For example, in Elasticsearch, or any other logging platform, searching for a specific error message may return incomplete results because the full stack trace is split across multiple entries.
Manning Book: Fluent Bit with Kubernetes
Learn how to optimize observability systems for Kubernetes. Download Fluent Bit with Kubernetes now!
Example: Python stack trace logs
Here’s an example of a typical Python exception log. When an exception occurs, Python outputs a detailed trace spanning multiple lines, showing where the error originated and how it propagated through the code.
2025-02-20 22:26:09,444 - ERROR - An error occurred:
Traceback (most recent call last):
File "/Users/final.py", line 25, in generate_errors
5 / 0 # Intentional ZeroDivisionError
ZeroDivisionError: division by zeroEach line would be treated as a separate log entry without proper multi-line log handling. In the image below, you can see how each stack trace line appears as an individual log entry.
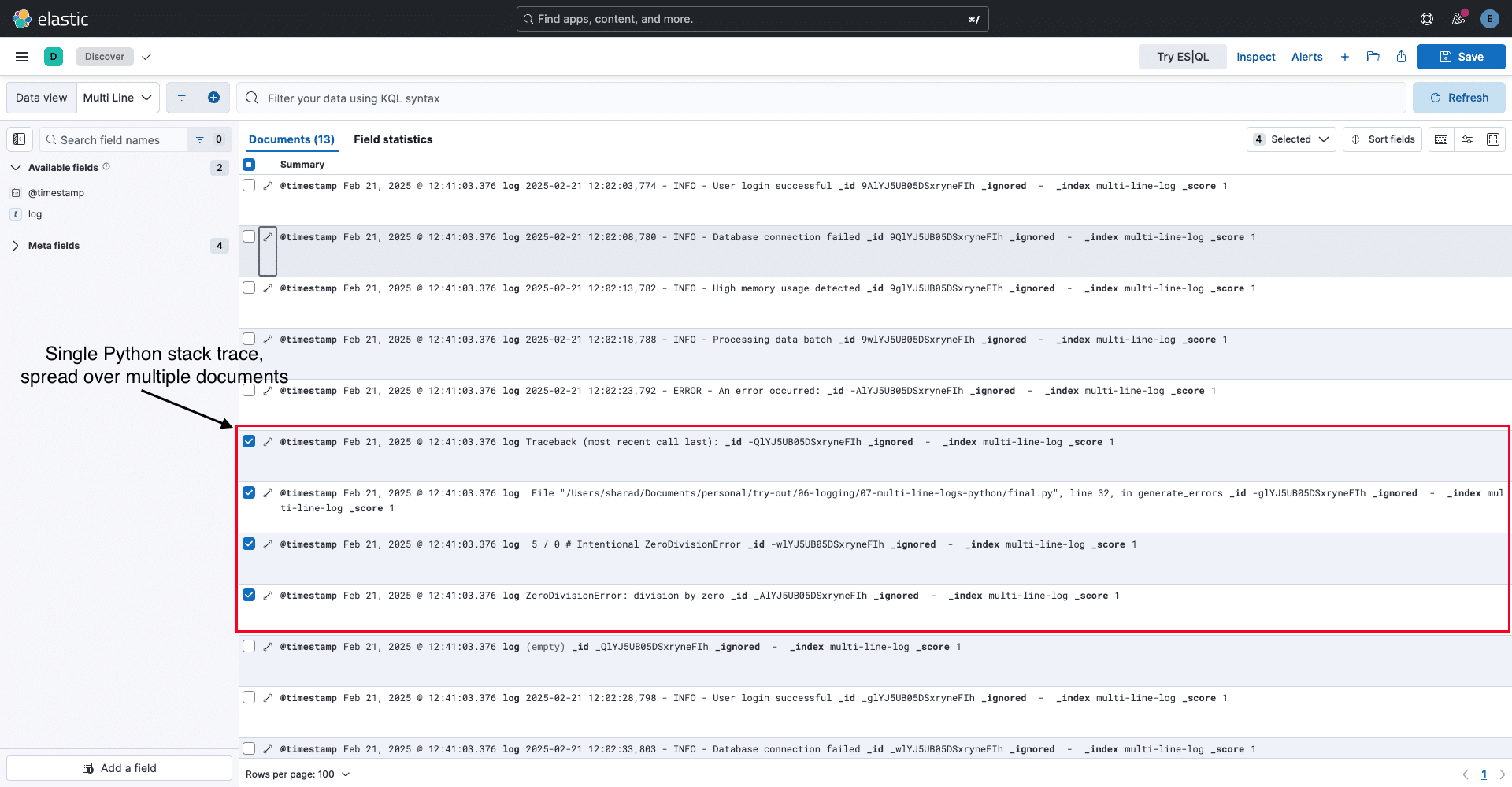
To address this, we need a way to group related lines into a single log entry. The solution? Fluent Bit Multi line Parser allows us to merge multi-line logs based on common patterns.
In the next section, we’ll explore how to configure Fluent Bit to handle multi-line logs effectively.
Multi-line parsing in Fluent Bit
Parsing is the process of converting unstructured or raw text data into a structured format that is easier to process and analyze.
In Fluent Bit, a multi-line parser is a component that processes log messages spread across multiple lines, concatenating them into a single log entry based on specific rules defined by regular expressions.
For example, the parser uses state and regex rules to detect the start of a multi-line message and then continues to capture subsequent lines that are part of the same message.
There are two ways to configure a multi-line parser:
- Built-in Multi-line Parser: Without any extra configuration, Fluent Bit exposes certain pre-configured parsers (built-in) to solve specific multi-line parser cases like
- CRI, Python, Go, Docker, and Java. Refer to this document to preview the built-in parser configuration.
Configurable Multi-line Parser: In addition to the built-in parsers listed above, you can define your own multi-line parsers with your rules through the configuration files.
To know more about multi-line parsers, refer to this documentation.
Parsing multi-line logs: Input stage vs. filter stage
When working with multi-line log parsing in Fluent Bit, you have two primary options for where to handle the concatenation of related log lines: at the input stage or the filter stage. Each approach has distinct characteristics and performance implications. Let’s explore both.
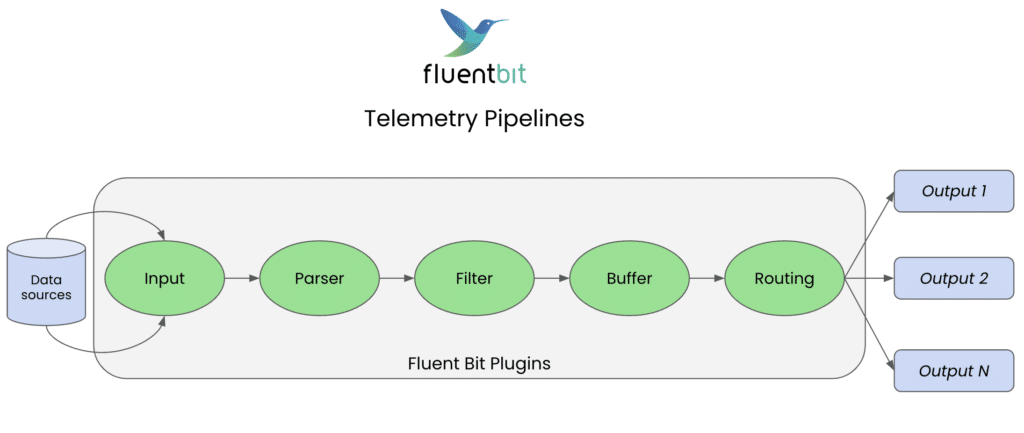
Input stage multi-line parsing
At the input stage, multi-line parsing is applied immediately after the data is ingested—for example, when using the tail input plugin to read log files. Here, the parser’s rules are used to group log lines that belong to the same context into a single record before any further processing occurs. This method ensures that the log’s complete structure is preserved from the moment of ingestion, making it ideal for scenarios where downstream processing (e.g., filtering, routing, or output formatting) depends on having the full log entry intact.
A key advantage of this approach is performance. Since concatenation happens as the log file is being read, it avoids the overhead of buffering and reprocessing later in the pipeline.
Filter stage multi-line parsing
designed to reunite log lines that belong to a single context—like stack traces or multi-line application logs—but were split into separate records during ingestion.
However, this approach comes with some nuances:
- Performance Consideration: Concatenating logs at the filter stage is less efficient than at the input stage. The Fluent Bit documentation recommends using the tail plugin’s multi-line support for log files whenever possible, as it processes logs during ingestion rather than after.
- Buffering Behavior: When the Buffer option is enabled, the filter holds messages until they’re fully concatenated or a timeout is reached. Without buffering, it processes one chunk at a time, which may not work well for inputs that send multi-line messages across separate chunks.
- Pipeline Positioning: The multi-line filter should be the first filter in your pipeline. Since it re-emits concatenated records to the pipeline’s head, any filters placed before it will process the logs twice—once before concatenation and once after. The filter ignores its own re-emitted records, but other filters won’t.
Single Filter Limitation: You can’t configure multiple multi-line filters with overlapping tags, as this creates an infinite loop. Instead, use a single filter with a comma-separated list of parsers (e.g., multiline.parser = parser1,parser2).
Choosing the right approach
- Use input stage parsing (e.g., via tail) for log files or containerized logs where performance is critical, and the log structure is known at ingestion time.
- Use filter stage parsing when logs are ingested as separate records (e.g., via a network input) and need to be recombined later or when you need flexibility to apply parsing rules after initial processing.
Conclusion
Multi-line logs are helpful for debugging but can complicate analysis if not managed properly. Fluent Bit provides a robust solution by consolidating these logs into single, structured entries with its multi-line parser, whether used at the input or filter stage. By selecting the right approach—input for performance or filter for flexibility—you can streamline troubleshooting and ensure critical details remain intact.
This blog is the first in a two-part series. Stay tuned for the next installment when we discuss handling multi-line with built-in parsers in Fluent Bit.
Buyer’s Guide: Telemetry Pipelines
Build a smarter telemetry pipeline. Download The Buyer’s Guide to Telemetry Pipelines


