

Fluent Bit is a widely used open-source data collection agent, processor, and forwarder that enables you to collect logs, metrics, and traces from various sources, filter and transform them, and then forward them to multiple destinations.
Fluent Bit version 2 introduced the concept of Processors, which, like Filters, enrich or transform telemetry data.
With the release of Fluent Bit version 4, a new feature was introduced: conditional log processing using processors. In this post, we will explore how to use Fluent Bit processors to modify logs based on their content conditionally.

Prerequisites
- Docker: Installed on your system
- Familiarity with Fluent Bit concepts: Such as inputs, outputs, parsers, and filters. If you’re unfamiliar with these concepts, please refer to the official documentation.
What are Processors?
Processors are components that modify, transform, or enhance data as it flows through Fluent Bit. Unlike filters, processors are tightly coupled to inputs, which means they execute immediately and avoid creating a performance bottleneck.
How are Processors Different from Filters?
While both processors and filters can manipulate data, there are key differences:
- Execution Point: Processors are tightly coupled to inputs and execute immediately, while filters operate in a separate pipeline stage.
- Performance Impact: Processors avoid creating bottlenecks since they don’t require buffering between stages.
- Configuration: Processors are only available in YAML configuration format.
- Scope: Filters can be implemented to mimic processors, but not vice versa.
Conditional Log Processing using Processors
Conditional processing enables you to selectively apply processors to logs based on the values of fields within those logs. This allows you to create processing pipelines that only process records that meet specific criteria, ignoring the rest.
You can turn a standard processor into a conditional processor by adding a condition block to the processor’s YAML configuration settings. These condition blocks use the following syntax:
pipeline:
inputs:
<...>
processors:
logs:
- name: processor_name
<...>
condition:
op: {and|or}
rules:
- field: {field_name1}
op: {comparison_operator}
value: {comparison_value1}
- field: {field_name2}
op: {comparison_operator}
value: {comparison_value2}
<...>Condition evaluation
The condition.op parameter specifies the condition’s evaluation logic. It can have one of the following values:
- and: A log entry meets this condition when all the rules in the condition.rules array is truthy.
- or: A log entry meets this condition when one or more rules in the condition.rules array is truthy.
Rules
Each item in the condition.rules array must include values for the following parameters:
| Parameter | Description |
|---|---|
| field | The field within your logs to evaluate. The value of this parameter must use the correct syntax to access the fields inside logs. |
| op | The comparison operator to evaluate whether the rule is true. This parameter (condition.rules.op) is distinct from the condition.op parameter and has different possible values. |
| value | The value of the specified log field to use in your comparison. Optionally, you can provide an array that contains multiple values. |
Rules are evaluated against each log that passes through your data pipeline. For example, given a rule with these parameters.
Our Use Case
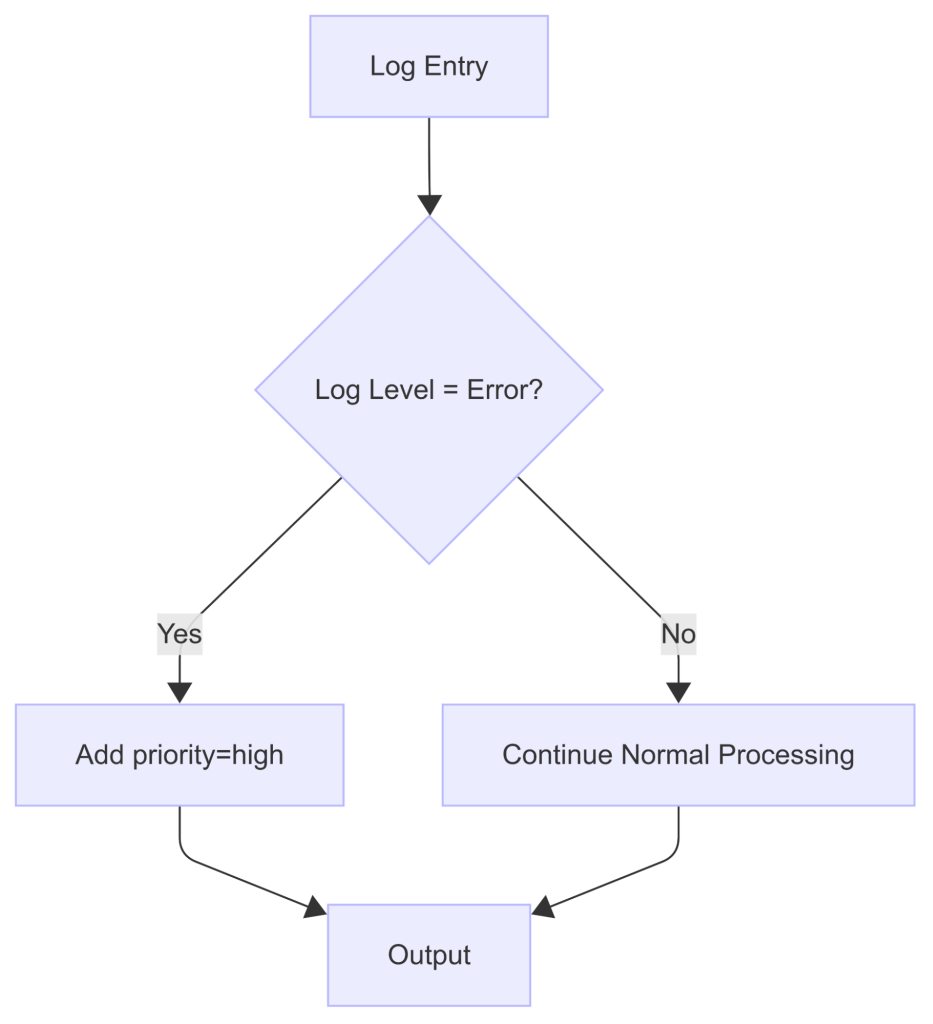
For our demonstration, we’ll implement a common scenario:
Objective: Automatically tag error-level logs with priority=high to enable special handling downstream.
This is valuable for:
- Triggering immediate alerts for critical errors
- Routing high-priority logs to dedicated analysis systems
- Ensuring error logs are retained longer than routine logs
Instructions
- Create the Fluent Bit directory
mkdir fluent-bit-conditional-demo
cd fluent-bit-conditional-demo2. Create the Input Log File
Create input.log file with the below content:
{"timestamp": "2023-10-15T10:30:00", "level": "info", "message": "User login successful", "user_id": 1001}
{"timestamp": "2023-10-15T10:31:00", "level": "warn", "message": "High CPU usage detected", "cpu": 85}
{"timestamp": "2023-10-15T10:32:00", "level": "error", "message": "Database connection failed", "service": "payment"}
{"timestamp": "2023-10-15T10:33:00", "level": "info", "message": "API request completed", "endpoint": "/api/v1/users"}
{"timestamp": "2023-10-15T10:34:00", "level": "error", "message": "Authentication failed", "user_ip": "192.168.1.105"}
{"timestamp": "2023-10-15T10:30:00", "level": "info", "message": "User login successful", "user_id": 2001}3. Create the Configuration
Create fluent-bit.yaml file with the below content:
service:
flush: 1
log_level: info
parsers_file: parsers.yaml
parsers:
- name: my_json_parser
format: json
time_key: time
time_format: '%Y-%m-%dT%H:%M:%S.%L%z'
time_keep: true
pipeline:
inputs:
- name: tail
tag: log.test
path: /test/input.log
read_from_head: true
parser: my_json_parser
# Apply processor to the input
processors:
logs:
- name: content_modifier
condition:
op: and
rules:
- field: "$level"
op: eq
value: "error"
action: insert
key: priority
value: high
outputs:
- name: stdout
match: '*'In the above configuration, we set a pipeline that reads log entries from a file, parses them as JSON, and prints them on STDOUT.
In the input section, the tail plugin reads the logs from /test/input.log file and adds a log.test tag to every record. The content_modifier processor then inspects each parsed record and, if the log level matches error, adds a new priority field. Finally, all processed logs are routed to the standard output.
4. Run the Container
docker run \
-v $(pwd)/input.log:/test/input.log \
-v $(pwd)/fluent-bit.yaml:/fluent-bit/etc/fluent-bit.yaml \
-ti cr.fluentbit.io/fluent/fluent-bit:4.0.8 \
/fluent-bit/bin/fluent-bit \
-c /fluent-bit/etc/fluent-bit.yaml5. Verify the Output
You should see output similar to:
[0] log.test: [[1756973650.919511219, {}], {"timestamp"=>"2023-10-15T10:30:00", "level"=>"info", "message"=>"User login successful", "user_id"=>1001}]
[1] log.test: [[1756973650.919514469, {}], {"timestamp"=>"2023-10-15T10:31:00", "level"=>"warn", "message"=>"High CPU usage detected", "cpu"=>85}]
[2] log.test: [[1756973650.919515761, {}], {"timestamp"=>"2023-10-15T10:32:00", "level"=>"error", "message"=>"Database connection failed", "service"=>"payment", "priority"=>"high"}]
[3] log.test: [[1756973650.919516677, {}], {"timestamp"=>"2023-10-15T10:33:00", "level"=>"info", "message"=>"API request completed", "endpoint"=>"/api/v1/users"}]
[4] log.test: [[1756973650.919517636, {}], {"timestamp"=>"2023-10-15T10:34:00", "level"=>"error", "message"=>"Authentication failed", "user_ip"=>"192.168.1.105", "priority"=>"high"}]
[5] log.test: [[1756973650.919518552, {}], {"timestamp"=>"2023-10-15T10:30:00", "level"=>"info", "message"=>"User login successful", "user_id"=>2001}]Notice that only the error logs (entries 2 and 4) have the priority: high field added.
Conclusion
Fluent Bit’s conditional processing feature provides a powerful way to selectively modify logs based on their content. This enables more sophisticated log processing pipelines, allowing you to:
- Apply different processing rules to different types of logs
- Add contextual information to specific log categories
- Create more intelligent routing decisions based on log content
By applying the techniques demonstrated in this guide, you can construct more sophisticated log processing pipelines that cater to the unique needs of your application and infrastructure.
Manning book: Logging Best Practices
Transform logging from a reactive debugging tool into a proactive competitive advantage.


