

Fluentd to Fluent Bit origin story
Fluentd was created over 14 years ago and still continues to be one of the most widely deployed technologies for log collection in the enterprise. Fluentd’s distributed plugin architecture and highly permissive licensing made it ideal as part of the Cloud Native Computing Foundation (CNCF) as a now graduated project.
However, enterprises drowning in telemetry data are now requiring solutions that have higher performance, more native support for evolving schemas and formats, and increased flexibility in processing. Enter Fluent Bit.
When and why to migrate?
Fluent Bit, while initially growing as a sub-project within the Fluent ecosystem, expanded from Fluentd to support all telemetry types – logs, metrics, and traces. Fluent Bit now is the more popular of the two with over 15 billion deployments and used by Amazon, Google, Oracle and Microsoft to name a few.
Fluent Bit also is fully aligned with OpenTelemetry signals, format and protocol, which ensures that users will be able to continue handling telemetry data as it grows and evolves.
Among the most frequent questions we get as the maintainers of the projects are:
- How do we migrate?
- What should we watch out for?
- And what business value do we get for migrating?
This article aims to answer these questions with examples. We want to help make it an easy decision to migrate from Fluentd to Fluent Bit.
Why Migrate?
Here is a quick list of the reasons users switch from Fluentd to Fluent Bit:
- Higher performance for the same resources you are already using
- Full OpenTelemetry support for logs, metrics, and traces as well as Prometheus support for metrics
- Simpler configuration and routing ability to multiple locations
- Higher velocity for adding custom processing rules
- Integrated monitoring to better understand performance and dataflows
Whitepaper: What is a Telemetry Pipeline?
Learn how telemetry pipelines help organizations control their log data from collection to backend destination.
Fluentd vs. Fluent Bit: What are the Differences
Background
To understand all the differences between the projects, it is important to understand the background of each project and the era it was built for. With Fluentd, the main language is Ruby and initially designed to help users push data to big data platforms such as Hadoop.The project follows a distributed architecture, where plugins are installed after the main binary is installed and deployed.
Fluent Bit on the other hand, is written in C, with a focus on hyper performance in smaller systems (containers, embedded Linux). The project learned from Fluentd’s plugins and instead opts for fully embedded plugins that are part of the core binary.
Performance
The obvious difference and main value of switching from Fluentd to Fluent Bit is the performance. With Fluent Bit, the amount of logs you can process with the same resources could be anywhere from 10 to 40 times greater depending on the plugin you are using.
Fluent Bit was written from the ground up to be hyper performant, with a focus of shipping data as fast as possible for data analysis. Later on, performance was found to be efficient enough that more edge processing could be added without compromising on the mission to make the agent as fast as possible.
Routing
Other parts of Fluent Bit evolved from challenges encountered with Fluentd, such as buffering and routing. With Fluentd multirouting was an afterthought and users needed to “copy” the data streams to route data to multiple points.
This made configuration management a nightmare, in addition to essentially duplicating the resource requirements for routing that data.
In Fluent Bit the buffers are stored once, which allows multiple plugins to “subscribe” to a stream of data. This ensures that data is stored once and subscribed many times allowing for multirouting without the trade-offs of performance and configuration fatigue.
Telemetry signal focus
While Fluentd was initially a data shipper, it grew into a logging agent used within projects such as Kubernetes and companies like Splunk. Fluent Bit on the other hand started as an embedded metrics collector with log files coming in after. As Fluent Bit adoption started to outweigh Fluentd’s functionality, capabilities such as OpenTelemetry logs/metrics/traces, Prometheus Scrape and Remote Write Support, eBPF and profiling support were all added.
Today Fluent Bit is aligned with OpenTelemetry schema, formats and protocols and meant to be a lightweight implementation that is highly performant.
Custom processing
Fluentd and Fluent Bit have many of the same processor names, but when it comes to custom processing the options are quite different.
With Fluentd the option is `enable_ruby`, which allows custom Ruby scripts within a configuration to perform actions. This can work effectively for small tasks; however it has a large penalty as logic gets more complicated, adding more performance bottlenecks.
With Fluent Bit, custom processing is done in the language Lua, which gives tremendous flexibility. However, unlike Fluentd, Fluent Bit’s Lua processor is quite performant and can be used at scale (100+ TB/day).
Custom plugins
Both projects allow custom plugins to help you connect with your source or destination. With Fluentd, these custom plugins are “Ruby Gems” that you can download and install into existing or new installations or deployments. With Fluent Bit, custom plugins are written and compiled in Go. There are also new initiatives for writing custom plugins in any language you want and compiling them into WebAssembly.
One lesson we learned from Fluentd’s distributed plugin architecture was the number of plugins can increase exponentially. However, the quality and maintenance required generally left many of the plugins abandoned and unsupported. With Fluent Bit, plugins are all incorporated into the source code itself, which ensures compatibility with every release.
Custom plugins still remain independent of the main repository. However, we are looking at ways to allow these to also share the same benefit of native C plugins within the main GitHub repository.
Monitoring
Understanding how data is traversing your environment is generally a top request from users who deploy Fluentd or Fluent Bit. With Fluentd, enabling these settings could require complicated configuration via “monitor_agent” or using a third party prometheus exporter plugin. These monitoring plugins also add maintenance overhead for Fluentd, which can affect performance.
Fluent Bit has monitoring as part of its core functionality and is retrievable via a native plugin (`fluentbit_metrics`) or scrapeable on an HTTP port. Fluent Bit’s metrics also incorporate more information than Fluentd’s, which allows you to understand bytes, records, storage and connection information.
How to get started with a Fluentd to Fluent Bit migration
The next question we’re answering is: How do you get started?
The first important step is to understand how Fluentd is deployed, what processing happens in the environment and where data is flowing.
What you don’t need to worry about:
- Architecture support: Both applications support x86 and ARM.
- Platform support: Fluent Bit supports the same and more as Fluentd does today. Legacy systems may differ, however it is important to note those are not maintained in either OSS project.
- Regular expressions: If you built a large library of regular expressions using the Onigmo parser library, you can rest comfortably knowing that Fluent Bit supports it.
Deployment
Deployed as an Agent (Linux or Windows Package)
When Fluentd is deployed as an agent on Linux or Windows, its primary function is to collect local log files or Windows event logs and route them to a particular destination.Thankfully, Fluent Bit’s local collection capabilities are equal to Fluentd’s, including the ability to resume on failure, store last log lines collected and local buffering.
Deployed in Kubernetes as a DaemonSet
If Fluentd is running as a DaemonSet in your Kubernetes cluster, you should first check the image that is running. As Fluentd has distributed plugins, the DaemonSet image may have specific plugins included, which ensures you can go directly from reading Kubernetes logs to the end destination.
This example has OpenSearch and Kafka included as plugins, so you should validate that the image you are using has the same plugins as Fluent Bit. Fluent Bit also supports Kubernetes enrichment on all logs, giving data around namespace, pod, labels and more.
Deployed as an Aggregator / Collector
If your Fluentd is deployed collecting logs from syslog, network devices or HTTP requests, you can first verify that Fluent Bit has the same capability. For example, Fluent Bit has syslog, TCP, HTTP and UDP plugins that can cover a majority of these use cases.
In addition, Fluent Bit also can receive OpenTelemetry HTTP1/gRPC, Prometheus Remote Write, HTTP gzip and Splunk HTTP Event Collector (HEC) as additional inbound signals.
Adding a Telemetry Pipeline
When migrating from Fluentd to Fluent Bit, we would also recommend looking at adding a Telemetry Pipeline in the middle of the agents and the destinations. This allows you to move larger pieces of processing logic within Fluentd agents downstream.
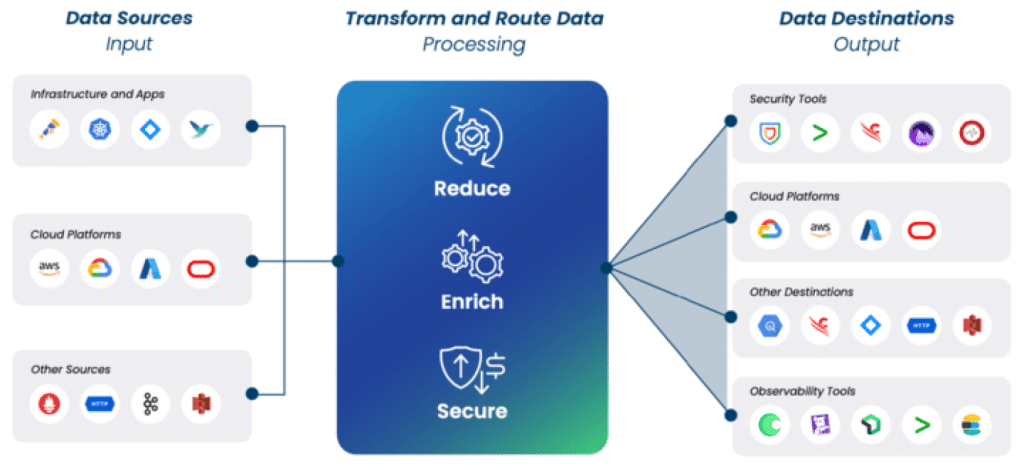
Configuration
The configuration syntax between Fluentd and Fluent Bit is vastly different. While both have started to support YAML more recently, most legacy Fluentd configurations will still be written in the domain-specific configuration language that is XML-esque.
Some general notes:
- Look at validating a single plugin at a time, and then at expanding to a single route (such as system logs to OpenSearch).
- Buffering and thread settings are not as important within Fluent Bit.
- Security settings should be similar.
When in doubt, reaching out to the Fluent community is useful in helping with some of the more granular settings.
Custom Plugins
When migrating, it’s important to ensure that Fluent Bit supports all plugins (sources and destinations)t. You should also check that it supports particular settings around authentication, authorization or access. This will be a manual process that can take some time. However, this will also allow you a chance to revisit decisions on specific data formats or plugin settings that you made in the past.
Custom Processing Logic
If you have labels, filters or other processing logic within Fluentd, it is important to note the functionality you are trying to achieve. While it may seem like just swapping those filters over might be easiest, you should also look at ways to migrate those directly into Fluent Bit processors. And if you have a fair amount of custom Ruby, you can use large language models (LLMs) to help convert it into suitable Lua.
Migrating Portions at a Time
You don’t need to migrate all your functionality at once. Because Fluent Bit is lightweight and performant, you can look at ways to have each agent handle different portions of the workload. Over time you can follow the logic above to continue migrating without having to worry about log collection disruptions.
Conclusion
While migrating from Fluentd to Fluent Bit might seem like an enormous task, you have many options about how to attack and where to focus to achieve the highest impact. Of course migrations are also a great time to re-evaluate certain logic for improvement and even introduce new architecture patterns such as a telemetry pipeline.
If you are looking for guided or assisted help, let me know. I have helped many folks migrate from Fluentd to Fluent Bit and even assisted with modernizing certain portions to a telemetry pipeline.
Frequently Asked Questions
Why migrate from Fluentd to Fluent Bit
With Fluent Bit you will get higher performance for the same resources you are already using; full OpenTelemetry support for logs, metrics, and traces as well as Prometheus support for metrics; simpler configuration and routing ability to multiple locations; higher velocity for adding custom processing rules; and integrated monitoring to better understand performance and dataflows.
What are some differences between Fluentd and Fluent Bit>
With Fluentd, the main language is Ruby and initially designed to help users push data to big data platforms such as Hadoop. Meanwhile, Fluent Bit is written in C, with a focus on hyper performance in smaller systems (containers, embedded Linux).
Can Fluentd and Fluent Bit work together?
Yes Fluent Bit and Fluentd can work together, which means it’s possible to capture from more sources by using Fluentd and introduce the data into a Fluent Bit deployment. The Forward plugin has a defined standard that Fluent Bit and Fluentd both use. Some external products have also adopted this protocol so they can be connected directly to Fluent Bit.
Whitepaper: Getting Started with Fluent Bit and OSS Telemetry Pipelines
Getting Started with Fluent Bit and OSS Telemetry Pipelines: Learn how to navigate the complexities of telemetry pipelines with Fluent Bit.


