")

Much like any company that makes software its business, Chronosphere builds a large and complicated product, in our case, a large-scale distributed architecture depending on complex open source projects, including M3 (jointly maintained by Chronosphere and Uber). This project requires an equally large and ideally less complicated test suite to ensure that bugs do not make their way into customer production environments.
Our test suite includes common tests you may expect, and others focused on scale, resilience, performance, and other tricky parts of distributed systems. This post explains each suite ordered by how easy it is for engineers to fix any detected issues.
The suite life of test suites
Unit tests
Tried and true, unit tests separately verify the functionality of each function and object, and form the backbone of testing for nearly every software team. Unit tests are great at asserting pre-conditions and post-conditions for functions to let developers confidently compose them, knowing that conditions will hold for inputs and outputs. Chronosphere has a decent level of test coverage, and CI processes enforce maintaining that coverage using Codecov. But like every software company, there’s always room for more coverage.
Fuzz tests
We use property-based testing to generate valid random data and verify it performs as expected for particularly complex functions, specifically those where edge cases are impossible to generate manually. For example, testing time series compression encoding/decoding logic has proven useful in exposing edge cases. We use Leanovate’s gopterimplementation of QuickCheck as a powerful testbed for fuzz tests.
Integration tests
Integration tests are used for testing complex interactions between M3 components, including: M3DB, M3 Coordinator, and M3 Aggregator.
The integration tests programmatically create instances of M3 components to test, seeding them with data and then running validations against them to ensure expected results. A few of these integration tests use fuzzed test data to help sniff out edge cases.
Dockerized integration tests
A different flavor of integration test that sits a little higher in the stack.
Our regular integration tests often seed test data directly into M3. These tests instead try to model a small part of the full data lifecycle against built images of M3 components running in Docker. An example of this type of test is this prometheus write data test (warning: this test has a lot of lengthy bash script, here be dragons). The test writes data using the remote write endpoint in M3 coordinator, then verifies the read by querying for it through the coordinator query endpoints. The tests have the downside of being (partially) written and run in bash, making them more difficult to write, run, and debug, but catching issues in these more real-world situations is worth the pain.
An aside on environments
The test suites above run on development stacks of varying levels of complexity:
- Unit tests ensure correctness on underlying code.
- Integration tests run on simulated backends.
- Dockerized tests run on VMs against fully built images.
The straightforward requirements for these suites allow them to be easily run as part of our CI pipeline, but we also run other suites against environments more closely approximating production; the tests in the next sections run against two full-sized, production-ready stacks.
- “Meta”, which is an environment that we at Chronosphere have set up to monitor the production deployments of our customers
- “Mirrored”, which is a stack that is a functional copy of the meta environment, with incoming writes dual-emitted to both of these environments.
These environments are great at representing how Chronosphere’s system performs under real-world conditions, as they are real-world conditions.
Scenario tests
These tests sit yet further up in the stack, running in Temporal (a tool for orchestrating complex applications; we will be publishing a deep-dive into our usage of Temporal soon, watch this space) against the mirrored environment.
These tests run broader “scenarios” rather than the integration tests, and they run them in an environment taking a realistic number of reads and writes. The tests help measure how well changes will perform in an environment running at scale, including custom functionality and extensions built on top of core M3 functionality. For example, one of our scenario tests adds, and then removes, a node to an M3DB cluster to ensure bootstrapping works as expected without read or write degradation. The scenario test suite runs continuously against the head of release candidate branches and the master branch to ensure confidence in the current release, and to catch regressions as soon as they merge.
Dogfooding in meta
Before releasing to production instances, we deploy release candidates to the meta environment for several days. During this period, all engineers using the environment can report any issues they find with the build. If they are significant, we release a hotfix branch and promote it to a release candidate after some basic smoke testing to manually verify that the hotfix has actually fixed the underlying issue, allowing our Buildkite CI pipeline to pick it up. The CI process automatically runs each of the above suites, promoting the release candidate to meta after successful completion.
Gaps in our test coverage
These suites make up our safe release stack, which provides confidence that a release candidate meets quality and reliability expectations for release to customers. However, these suites have shortcomings: they use synthetic data, act on a confined part of the stack, or both. In practice, this has led to missing some tricky edge cases or unexpected interactions that resulted in real-world impact and service degradation to customers.
M3 is a complex system consisting of multiple distributed components, which makes it difficult to test with a high degree of confidence. This complexity makes it difficult to test holistically, especially when introducing scale, timings, failovers, or a million other distributed systems issues. For further information and a deeper dive into how these components can fit together, and what happens to actually persist a write within an M3, the architecture docs are a good place to start.
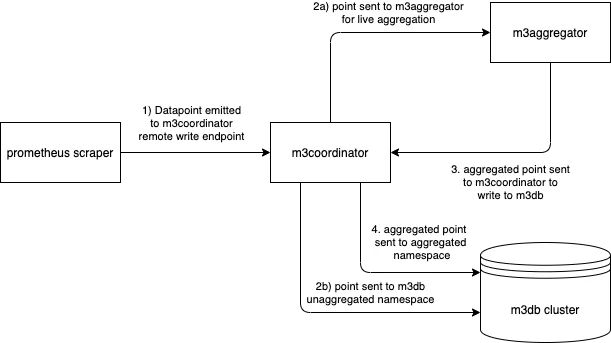
Dogfooding release candidates that have passed all relevant test suites before reaching the meta environment can help engineers catch issues, but it’s not a perfect process. Internal users can ignore flakiness in features, or not notice edge cases in queries that aren’t often used internally or on dashboards that engineers rarely look at. On top of this, some issues only show up when running at high write load or high query load, which is difficult to emulate consistently and catch before confidently releasing to production.
Patching the holes
In summary, the test suite is comprehensive, but not comprehensive enough to catch issues that affect customers’ experience and business. We needed something to fill those shortcomings by emulating and testing environments more like those used by our customers. Keep your eyes open for the next post on the topic, coming in a couple of weeks, where we dig deep into what we ended up creating and how it works to give us the confidence that we need.
Read part two of my blog series to continue the discussion: Comparing queries to validate Chronosphere releases.


