")


How telemetry pipelines help
When getting started with monitoring, it is tempting to take the simplest route and have your applications send logs, metrics, spans and events directly to an observability platform. As time goes on and the system sprawls across multiple regions, clusters and clouds, solely relying on applications to generate and send off their telemetry means accepting quite a bit of risk. Even while your system is small and manageable, this approach can still backfire by dropping data, leaving you to troubleshoot in the dark.
Enter telemetry pipelines! Think of a telemetry pipeline as a microservice whose one job is to get telemetry where it needs to go — reliably, efficiently and flexibly. For you this means escaping endless cycles of reconfiguration and frees up resources so your application can focus on its core business logic.
Sound too good to be true? Let’s look at your life with and without a telemetry pipeline and then run through the three primary reasons you need one.
Make data arrive safely
You need a telemetry pipeline for the same reasons you need a service mesh. Imagine your system is a bustling city. A service mesh is like a great public transit system that makes sure people move efficiently between locations. Think of your application’s logs, metrics, events and spans as mail packages and the telemetry pipeline as the central logistics hub that coordinates package pick up and ensures reliable delivery to destinations.
You don’t want your application to make a trade-off between user experience and delivering telemetry data. When an application is responsible for both generating this data and making sure it’s successfully ingested by other platforms…that’s asking a lot! Direct handling of buffering, retries, routing and compression strains app resources and can — in the worst case — result in dropping telemetry and bringing down the application. A telemetry pipeline makes sure that your data arrives safely, efficiently, and with minimal friction for you and your applications.
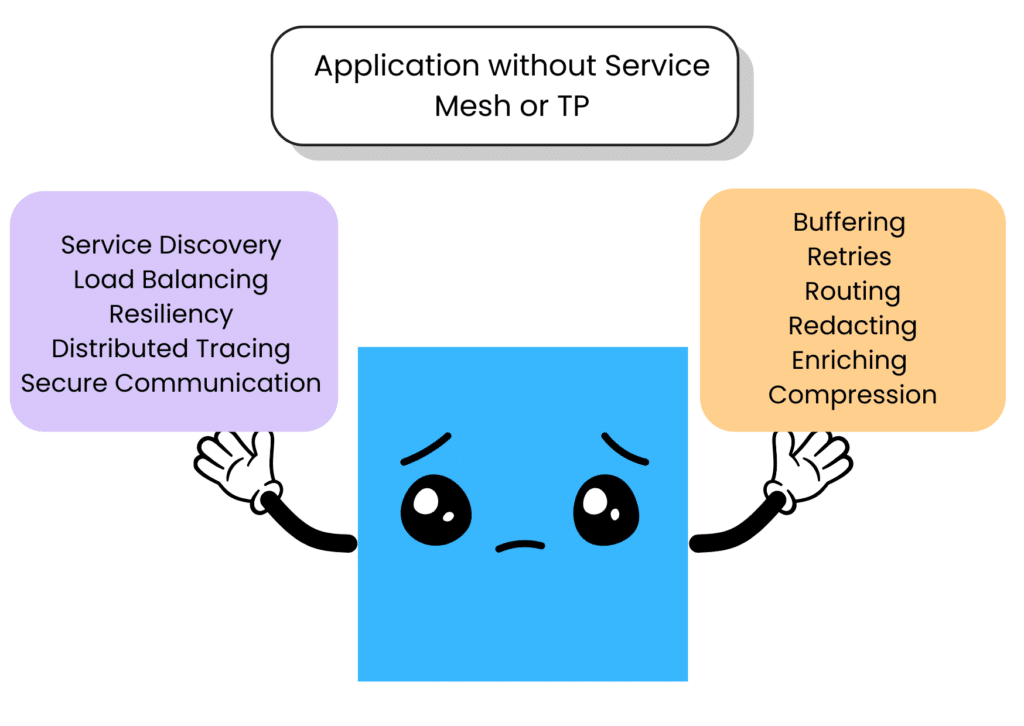

Life without a telemetry pipeline
Picture this: your organization is managing dozens of microservices, each churning out tons of telemetry about performance, errors, and usage. While you are juggling development responsibilities for several services your team owns, your colleagues in Security need to make sure no PII leaves your network. They also need to ensure data makes it to a SIEM in order for monitoring. SRE is tasked with ensuring the infrastructure is solid and that your application’s logs, metrics, events, and spans reliably reach the observability and monitoring platforms.
Of course leadership is always asking if we really need all this data all the time, because from the outside its unclear if the organization is getting increased benefits along with the increased costs.
Without a centralized system to handle all these competing needs, it’s only a matter of time before the cracks begin to show.




Telemetry toil: Updates that never end
Applications are responsible for shipping telemetry, and, as a service owner, you are on the hook for managing the configuration. This may not sound like a big deal at first. And it wouldn’t be if “set it and forget it” was a viable logging strategy. But, alas, change is the only constant in life. When service owners are responsible for tweaking telemetry, and centralized teams like SRE and Security need to delegate and coordinate changes across the system, this type of toil introduces a tension between teams.
One source of change is implementing and maintaining telemetry standards to make sure that across the many languages, frameworks, and stacks within a system, there are standard metadata fields available. If you remember the iPod days — or have experience manually managing your music collection — then you know the pain of having multiple records for artists like “ABBA”, “Abba”, “abba.” Back then there weren’t good options if you wanted to pull up the full list of songs for ABBA since they were treated as separate artists in the database.
Similarly, in order for a standard to be useful, there needs to be compliance across the board. With software systems, there are lots of bits of metadata that are helpful to include across all services — like the environment, cluster, region, etc that a pod is running in. This metadata is helpful when it’s applied to everything across the board, and less helpful if only 40% of applications comply. Without a telemetry pipeline, standardizing labels from cloud-region to cloud_region can clog up your backlog and ensuring compliance. This means SREs need to go app by app to request config changes and redeploys from teams and make sure changes take effect.
Another consideration is that the tooling and vendors that support your use cases and architecture today may not be the best fit a couple years down the line. Coupling shipping telemetry to application configuration entrenches existing vendors because the coordination and engineering hours needed to evaluate and migrate platforms can be prohibitive. Think about how untenable it would be to evaluate multiple vendors if each one you are considering requires opening a few dozen PRs just to get the data routed there to begin an evaluation pilot. Rinse and repeat at the end of the evaluation to remove the not chosen vendors.
With a telemetry pipeline a change — like standardizing labels from cloud-region to cloud_region — can be made by one time by one SRE in one place.
A telemetry pipeline offers a central place to make updates — whether that’s adding a new label like oncall_team across every service or adding a new destination for logs. When it’s time to roll out changes—like adding or removing destinations, updating metadata standards, or enforcing compliance rules—a telemetry pipeline gives you one central place to make updates. No more Security or SRE teams chasing down developers with last-minute requests or ultimatums.
System-wide standards that are easy to implement, enforce, and adjust make life better for everyone. Consistently formatted, easily searchable data means smoother troubleshooting, especially for issues that cross teams or domain boundaries.
Blind spots make log troubles untraceable
In order for early detection and monitoring to be effective your telemetry data needs to be delivered to observability and security platforms in near real-time. When there are hiccups sending, processing or receiving telemetry you need to be able to quickly answer: Is data getting dropped? How much and from what services? How high is latency to get data to the backend?
Without a telemetry pipeline you may not have the visibility you need to understand what is going wrong and where.
Instrumentation libraries and SDKs are primarily tasked with generating logs, metrics and spans relating to applications requests, errors, and resource usage. Asking an SDK to also ensure that this data is reliably sent to multiple destinations is asking a lot! Making sure that this data gets to where it needs to go means handling intermittent failures with retries and buffering or queueing data which can be a bit of a mixed blessing because if it isn’t done right you have the potential for data to queue up too much and cause the application to OOM and get caught in a crash loop just because it couldn’t ship telemetry to the configured destinations. Even if that SDK had helpful data, it’d get dropped leaving you stuck with more questions than answers.
3 challenges Telemetry Pipelines solve
1- Bring down ballooning bills
No one has a blank check for observability. Especially when it comes to the firehose of telemetry at cloud native scale. Your organization has a service or product/platform that it cares about keeping up and running….to a point. Managing volume (and thus cost) of this data has SRE teams playing whack-a-mole optimizing configuration service by service, forced to aggressively sample prioritizing the cost of the data not the value it brings, or upending your sprints with urgent requests to audit your services.
2- Turn blind spots into bright spots
When logs don’t reach their destinations, a telemetry pipeline gives you the visibility to figure out exactly where things went wrong. Is the issue in the pipeline itself, the source, or the destination? With meta-monitoring data about your data, you can drill down and identify the affected areas quickly, saving valuable time. This same data is a huge win for capacity planning and scaling. A centralized view with clear labels lets you track telemetry volumes across services and components, so you can spot trends and prepare for seasonal traffic patterns.
3- Dial in the data that matters most
If you’ve been spending more time wrestling with telemetry costs than actually using the data to improve your system, a telemetry pipeline might just save your sanity.
By filtering out duplicates and dropping unnecessary noise you can cut down the amount of data shipped to all your destinations. Since many platforms charge based on how much data you store and process, trimming the flow leads to some serious cost savings. But even better is that it makes the data you actually keep more useful, really it’s all about getting more value out of your data.
Conclusion
Telemetry pipelines give you the tools to handle the endless stream of logs, metrics, events, and spans your applications generate. They’re a scalable, centralized way to make sure this critical data gets where it needs to go—whether that’s your SIEM, observability platforms, or long-term storage—without dragging your system down with extra complexity.
I think Anurag Gupta put it best “Observability can be seen as a journey. People can start with simple monitoring, then evolve, and start adding more data sources. The journey starts at the place where the data is created and continues towards the place where debugging, diagnosing, and getting insights happens. Telemetry pipelines see the place where data gets generated, contextualized, processed, and routed as the first mile in that journey.”
The benefits start as soon as you do. Why let the growing pains pile up? The sooner you bring a telemetry pipeline into the mix, the sooner your team can focus on what really matters: delivering value. What’s stopping you from starting today?
Evaluating Telemetry Pipelines?
Time to read the Buyer’s Guide to Telemetry Pipelines


