")

Observability Pipelines: Transforming telemetry data management
An observability pipeline (also referred to as a “telemetry pipeline”) serves as middleware in your data infrastructure, to help you more easily manage your telemetry data. Unlike traditional log forwarders that simply move data from point A to point B, observability pipelines support multi-vendor data routing. They also provide sophisticated data transformation capabilities to ensure data is in the optimal format for its purpose.
Observability pipelines help you do the following:
- Collect data from your existing log collection agents, such as Splunk Universal Forwarders, Fluent Bit agents, Open Telemetry Collectors.
- Pre-process data – transform, enrich, filter, and more – in flight.
- Route it to any destination, including observability platforms, SIEM platforms, and object storage targets.
Quantifying the impact: Business benefits of observability pipelines
The implementation of an observability pipeline brings immediate and tangible benefits to organizations struggling with data management.
Reduce observability and SIEM costs
Rather than blindly forwarding all data to expensive platforms, telemetry pipelines can filter and aggregate information, significantly reducing ingestion volumes while preserving valuable insights.
One enterprise we worked with cut their Splunk costs by 25%, saving $3 million annually, simply by filtering out redundant/low-value data and trimming excessive fields.
Improve MTTR by upleveling data quality
Teams use an observability pipeline to improve data quality in multiple ways. You can:
- Align timestamps across sources
- Ensure field names follow consistent patterns
- Reshape data to align with a uniform schema (in more ambitious cases)
This standardization dramatically reduces the mean time to resolution (MTTR), as teams spend less time deciphering log formats and more time solving actual problems.
Simplify your observability architecture
The architectural benefits are equally compelling. Teams commonly adopt multiple backends for log data. For example, your infrastructure team, application team, and security team all might use different log analysis tools.
In the past, this meant the team responsible for logging would manage configurations, monitor agent health, and roll out updates across several disjointed collectors and data pipelines.
Observability pipelines help teams centralize data management into a single, coherent interface. This simplification not only reduces operational overhead but also improves reliability and maintainability of the entire observability stack.
Anatomy of an observability pipeline: Core components and functionality
Understanding how observability pipelines work requires familiarity with their three fundamental components: data sources, processing rules, and data destinations.
Pipeline architecture: From input to output
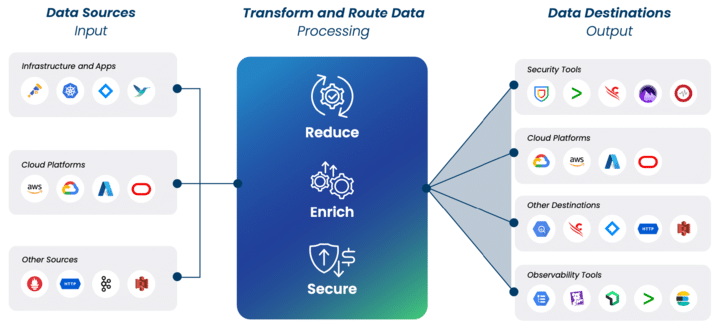
Data sources: Capturing telemetry at scale
Modern applications generate metrics, events, logs, and traces (MELT data) from countless sources:
- Containerized and monolithic infrastructure
- Applications your team builds and runs in house
- Network resources, like firewalls, content delivery networks, and application load balancers
- SaaS applications, like Okta and Salesforce
…and more. Observability pipelines collect data from these resources in different ways. In some cases, they might run as an agent that displaces your existing log collector. In others, they listen to your existing data collection methods (e.g., FluentD or Datadog agents), capturing data through push and pull mechanisms.
Processing rules: The intelligent transformation layer
This is where observability pipelines truly shine. The processing layer applies sophisticated processing rules to transform your data in flight, before it reaches its destination. Common transformation use cases include:
- Structuring unstructured data: An observability pipeline helps teams transform unstructured logs into structured data by parsing raw text into a standardized format, such as JSON. Using parsing rules and data transformation, teams can extract meaningful fields and create consistent key-value pairs, making logs easier to query and analyze downstream.
- Redacting sensitive information and PII: Observability pipelines protect sensitive data by helping you redact PII from your logs before they leave your environment. Using pattern matching and data masking and obfuscation rules, teams can remove credit card numbers, social security numbers, email addresses, and other sensitive information while preserving the log’s analytical value.
- Filtering out unnecessary information: Telemetry pipelines reduce data volume by filtering out low-value logs before they reach expensive platforms. Teams can drop debug logs, remove noisy fields, eliminate duplicate entries, and sample high-volume events, keeping only essential data while maintaining visibility into critical information.
Data destinations: Flexible routing for optimal insights
The final component handles the routing of processed data to its ultimate destinations. Modern observability pipelines support a wide range of outputs:
- Observability platforms, like Splunk, Datadog, Elastic, and New Relic.
- SIEM tools, like CrowdStrike, Panther, and Graylog.
- Object storage targets, like Amazon S3, Google Cloud Storage, and Azure Blob.
- Real-time notification systems, like Slack and Microsoft Teams.
Supporting multiple destinations enables you to move data to the right place for its intended use case. For example, you might have long-term retention requirements for compliance. Moving these logs to Amazon S3 helps you meet your regulatory needs without going over budget.
Critical features for effective observability pipelines
When evaluating observability pipelines, several key capabilities deserve special attention:
- Support for open standards, such as OpenTelemetry and Prometheus, is particularly important. Open standards ensure long-term flexibility and prevent vendor lock-in.
- Advanced routing capabilities allow for sophisticated data distribution based on content, tags, or external lookups. Intelligent routing ensures data reaches the right destination – without creating additional engineering effort.
- Operational automation has also become essential. Modern pipelines should support automated scaling, load balancing, and self-healing capabilities. These features ensure reliability while minimizing operational overhead.
Observability pipelines in action: Real-world use cases
To help understand the value of observability pipelines, let’s explore a few common use cases.
Enhancing security: Real-time log enrichment for threat detection
Security teams often struggle with the lack of context in their log data. A suspicious login attempt might be logged, but without additional context, determining its risk level requires time-consuming manual investigation. An observability pipeline can automatically enrich these security events with crucial context like geolocation data, IP reputation scores, and known threat indicators. Imagine a security analyst receiving an alert not just about a failed login attempt, but one that immediately shows the attempt came from a region known for cyber attacks, using an IP address recently flagged for malicious activity.
Ensuring compliance: Automated PII protection in data streams
In today’s regulatory environment, protecting sensitive information is non-negotiable. The amount of GDPR fines imposed in 2023 reached $1.94 billion. Yet engineering teams frequently struggle to maintain perfect discipline around logging practices, occasionally letting sensitive data slip into log entries. An observability pipeline can help you identify and redact sensitive information before it leaves your environment.
Optimizing costs: Smart data processing for efficient observability
Cost optimization represents one of the most compelling use cases for observability pipelines. A financial services company facing rapidly growing observability costs implemented an observability pipeline. The pipeline performed several key functions:
- First, it implemented intelligent sampling of high-volume, low-value logs. Debug-level logs from healthy systems were sampled at a lower rate, while maintaining 100% capture of error and warning logs.
- Second, it normalized data formats across services, eliminating redundant fields and standardizing timestamps and field names.
- Finally, it aggregated similar events, converting high-volume log streams into more manageable metrics where appropriate.
The result was a 30%+ reduction in data ingestion volume with no loss of operational visibility.
The evolution of observability: From log forwarders to intelligent pipelines
The journey from simple log forwarders to sophisticated observability pipelines reflects the broader evolution of modern infrastructure. Initially, teams relied on vendor-specific tools to get data from point A to point B.
While these tools (e.g., Splunk Universal Forwarder and the Datadog Agent) provided advanced functionality, they also created vendor lock-in and lacked control to reduce data volumes in a sustainable manner.
Open-source tools like Fluent Bit and Vector emerged to address these growing needs, offering more flexibility in the form of multi-vendor routing, superior performance, and more advanced processing capabilities. However, these tools use a command line interface (CLI) and are managed in a distributed manner. In some cases, this can be difficult to maintain at scale.
Enterprise observability pipelines build on these foundations, adding easy-to-use management interfaces, advanced processing capabilities, and enterprise-grade support.
What's next for observability pipelines
Looking ahead, several trends are shaping the future of observability pipelines:
AI-powered data processing recommendations
Current observability pipelines offer AI-assisted processing rule creation. In the future, artificial intelligence will be helpful in providing proactive recommendations for data processing. By suggesting the optimal sample rates and filter data, engineering teams build effective telemetry pipelines in a fraction of the time and without expertise.
Native integration with log management and SIEM platforms
As the volume of telemetry data continues to grow, there’s an increasing need for tighter integration between observability pipelines and the platforms that consume this data. The future will likely see observability pipeline functionality being built directly into log management and SIEM platforms. This tighter integration will empower organizations to maximize the value of their observability data while maintaining control over costs and complexity.
More advanced stream processing at the edge
Stream processing in observability pipelines is evolving beyond basic data aggregation and traffic reduction. While today’s implementations primarily focus on aggregating logs and deriving edge insights, future capabilities will enable more sophisticated real-time analysis. Advanced stream processing will support complex pattern recognition, predictive anomaly detection, and intelligent data reduction at the source. This shift from simple aggregation to sophisticated edge analytics will help teams process and analyze data more efficiently before it reaches downstream systems.
Future-proofing data management: The strategic role of observability pipelines
As we look to the future, observability pipelines are becoming a critical part of modern data infrastructure. They represent not just a solution to current challenges around cost, complexity, and compliance, but a foundation for future data management needs.
Teams implementing these pipelines today are not just solving immediate problems – they’re building the flexibility and scalability needed to handle tomorrow’s challenges. Whether it’s adapting to new data sources, integrating with new analysis tools, or meeting evolving compliance requirements, a well-designed observability pipeline provides the foundation for effective telemetry data management.
The journey to effective observability is ongoing, but with the right pipeline in place, organizations can transform their data from a burden into a genuine strategic asset. As data volumes continue to grow and systems become more complex, the role of observability pipelines will only become more critical in maintaining efficient, cost-effective, and compliant data operations.
Remember: in the world of modern observability, it’s not just about collecting data – it’s about collecting the right data, in the right way, at the right cost. An observability pipeline makes this possible.
Explore next
Frequently Asked Questions
What is an observability pipeline?
An observability pipeline sits between your data sources and destination. It collects, processes, and routes telemetry data from various sources to multiple destinations. It acts as a central hub for managing metrics, events, logs, and traces (MELT data), enabling data normalization, transformation, and enrichment before forwarding to observability platforms, SIEM tools, long-term storage, or other tools.
How do observability pipelines help with data transformation?
Observability pipelines offer powerful data transformation capabilities, including:
- Structuring unstructured log data for easier analysis
- Normalizing timestamps and field names across different data sources
- Enriching logs with additional context, such as geolocation or threat intelligence
- Filtering out unnecessary information to reduce data volume
- Masking or redacting sensitive information for compliance purposes
These transformations ensure that data is in the optimal format for its intended use, improving analysis efficiency and reducing storage costs.
Can observability pipelines help reduce observability costs?
Yes, observability pipelines can significantly reduce costs associated with data management and analysis. By implementing intelligent data filtering, sampling, and aggregation, pipelines can reduce the volume of data sent to expensive observability platforms. For example, they can filter out low-value debug logs, aggregate similar events into metrics, and route less critical data to cheaper storage options. This data reduction and smart routing can lead to substantial cost savings without compromising on insights.


