

This is part two in a series on the Observability Hierarchy of Needs. We cover:
- How the Observability Hierarchy of Needs pyramid represents key areas of focus in a winning observability strategy
- Why the data layer factors into all other decisions made in an organization
- Using telemetry pipelines and open source technology to collect data
The previous article in this series laid out the foundations of the technology journey that many modern day engineers have been through. From bare metal all the way to cloud native container-based development, we’ve all been traveling on this fast-paced journey that has been a constant struggle with the amount of data being generated.
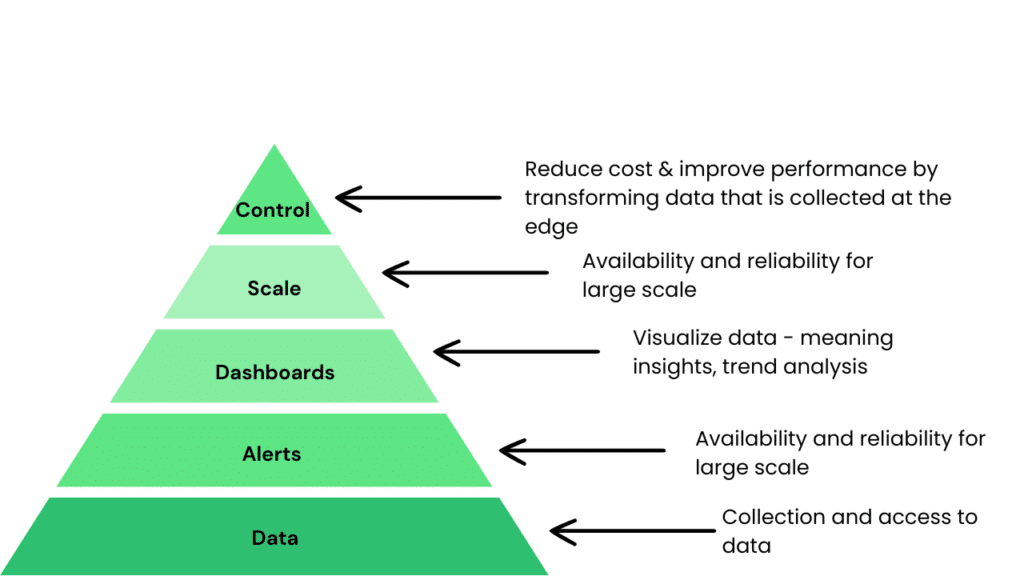
Realizing that data is the gold we need to mine, we suggested tackling this challenge by providing an effective observability solution to our organizations. To that end, we introduced Observability’s Hierarchy of Needs, where the five layers in the hierarchy are shown in a pyramid to represent key areas of focus when it comes to building a winning observability strategy.
Why the data layer is foundational
Just as in Maslow’s hierarchy of needs, the base layer for observability’s hierarchy of needs is the crucial component for survival in the cloud native world. This layer is the data layer, factoring into all other decisions made in an organization. None of the higher levels of the hierarchy can be pursued without first satisfying the base data needs of an organization.
It’s essential to satisfy this need by collecting and providing access to data in ways that are meaningful to our organization. If we are unable to satisfy this basic need, then visualizing what is happening and identifying failures — necessary to detect issues in a timely fashion — will hinder scaling our organization.
Data needs to be collected and accessed in a reliable and timely manner, including being able to uncover what is relevant data for our needs. No matter the source, or the destination — and during the data’s journey — we need to be able to collect it. We need tooling that allows us to collect our data from legacy systems, from infrastructure, from monolithic applications, and from modern cloud native applications that are based on microservices.
Using Telemetry Pipelines to collect data
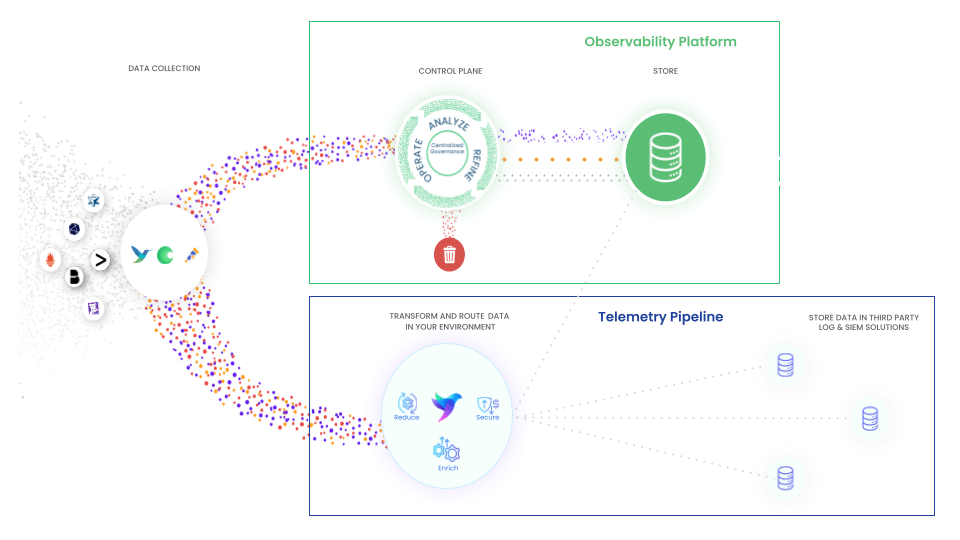
Collection can be done using telemetry pipelines, open source collectors, or other vendor solutions, but we need to ensure we are doing our best to leverage standard protocols.
Look for tooling like Prometheus for metrics collection and then provide standard query languages such as PromQL for use in other hierarchy layers. OpenTelemetry collectors provide a way to gather data using their standard of OpenTelemetry Protocol (OTLP).
For example, take a look at how Fluent Bit provides you with a very flexible way to:
- Input almost any source of data
- Transform that data as needed to ensure it’s using standard protocols
- And finally forward it to any output destination needed.
These tools all ensure that the data is both collected and available for access by higher layers in the hierarchy using standard protocols.
Only store the data you need
Essential to all this data that is being collected? Providing a way to determine what is really needed.
This can be achieved by providing insights at ingestion, before the data is put in expensive storage, so that we can only store the data we plan to use in later hierarchy layers. What good does it do to store all incoming data, only to discover that 60% of the data is unused by any later layers of the hierarchy?
If we can gain insights through a data control plane such that we can decide to drop or aggregate away data points we don’t currently need or use, we now have the data layer solution we need.
What’s next
This article laid out the Data layer from Observability’s Hierarchy of Needs, a foundational need that must be conquered in order to support all the other needs.
The next article in this series talks about the Alerts layer, where alerts and notifications are needed to help ensure high availability. Following that, we will cover the Dashboards layer for visualizing data and drawing insights. We will continue onwards to take a look at how with growth comes scale and how we need to be looking at ways to ensure high availability and reliability for large scale workloads. Finally, we conclude with an article on Control, the hardest need to attain.
Stay tuned for the next article in this series, where we will cover the Alerts layer.


