")

Using Temporal
Chronosphere has been using Temporal, an open source workflow orchestration engine, since late 2020 for three primary use cases:
- Deployment workflows in a proprietary deployment system.
- Automated cluster operations such as rolling restarts and migrating capacity.
- Scenario testing for release validation.
We recently spoke at Temporal’s meetup on the first use case – deployments – and the remainder of this blog will focus on how we built our own deployment system using Temporal along with some challenges and lessons learned along the way.
With the help of Temporal’s glossary, here are a few concepts and terms to help set context for the blog:
- Workflow: a durable function that is resumable, recoverable, and reactive.
- Workflow ID: a customizable, application-level identifier for a Workflow.
- Locks for services: distributed mutexes to coordinate Workflow execution.
- Activity: executes a single, well-defined action, such as calling another service, transcoding a media file, or sending an email.
Building our deployment system with Temporal
Chronosphere uses a hybrid between multi- and single-tenant architectures, in which we deploy a separate fully functioning Chronosphere stack within each of our tenants or customer environments. Because of this, engineers typically need to deploy changes to production for a combination of services to a set of tenants. So when thinking about our deployment system, we wanted to ensure engineers had options to control different aspects of the rollout, such as the order in which tenants and services are deployed, whether they are deployed in parallel or sequentially, how failures should be handled, etc.
This led to the following structure for deployment workflows:
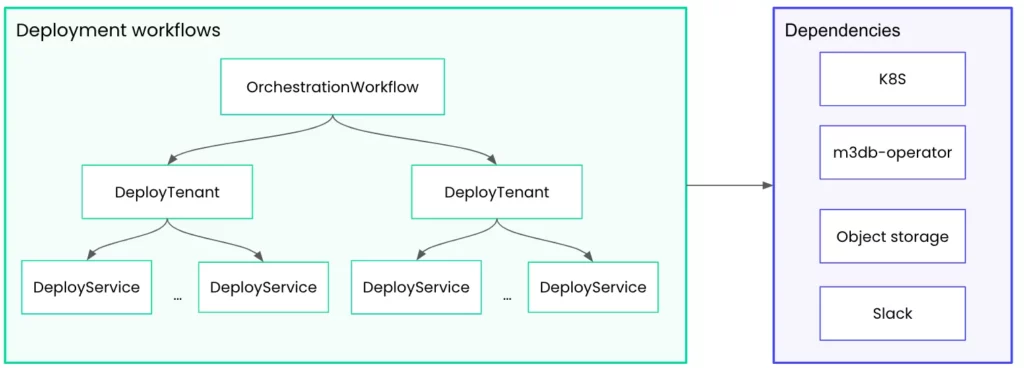
In this structure, there are three main workflows:
- Orchestration: controls the speed, the number, and the order of roll outs across tenants; initiates a DeployTenant workflow for each tenant.
- DeployTenant: controls the same aspects as Orchestration, but for services within one tenant environment; performs additional monitoring.
- DeployService: applies changes to a single service and waits for the rollout to complete.
Each of these workflows interact with external dependencies such as Kubernetes, m3db-operator, object storage, and Slack.
When building out this new, automated deployment system with Temporal, there were a few patterns and challenges we encountered along the way. See how we handled them below:
Challenge #1: Managing conflicting operations
To help set context, let’s further define workflow IDs. Workflow IDs are user-provided identifiers for a workflow. For example, our Orchestration workflow has the ID pattern “deploy:<cluster>/<deployment_id>”. Temporal allows you to ensure that no two workflows with the same ID are running at once, or that no two workflow IDs are ever reused.
From the early days of our deployment system, we wanted to make sure we didn’t have multiple deployments changing the same set of services in the same customer environment. Initially, we decided that we would allow only one running deployment in the customer environment by generating the ID for DeployTenant workflow, such as “deploy:<cluster>/<tenant>”.
This worked fine at first, but became difficult to manage as the complexity of the system and our engineering organization started to grow. With more customers, services to manage, and more engineers wanting to do deploys, we ran into challenges with the following use cases:
- Allowing deployment of different services in parallel for the same tenant.
- Blocking multiple deploys of the same service for the same tenant.
- Blocking changes from other workflows during a deployment (e.g. a rolling restart).
In order to resolve these challenges, we introduced a lock workflow to acquire a lock for services at the start of the DeployTenant workflow. By doing this, we are able to better control whether or not to proceed with changes or deployments to a tenant or set of tenants. We based this lock workflow on the mutex sample from Temporal, and then added additional functionality to increase usability for our use cases.
Challenge #2: Implementing additional safety checks
At Chronosphere, we provide mission-critical observability to our customers, and we wanted to ensure our deployment system met our high bar for safety and correctness. In order to make deploys more robust to failures, we wanted the deployment to be aware of changes in the system that happened outside of a workflow. For example, if an alert is triggered for a customer during a deploy of that customer, we want the system to make it seamless to mitigate the impact.
In order to do so, we introduced different activities to perform specific checks (such as NoCriticalAlerts, IsPodAvailable). In addition, we added helper functions to execute these checks in parallel with other workflow changes. If a check fails, then all other checks are canceled, the workflow is terminated, and the initiating user is notified. These additional safety checks have also been useful for release validation and cluster operations.
Challenge #3: Interacting with running workflows using Slack
While rolling out new software to production, we occasionally need to involve an engineer to make a decision. This is needed for a few reasons, for example:
- When rolling out a significant change, the engineer would want to roll out to one tenant first, validate, and then continue to the rest.
- If a critical alert starts firing, we want the user who initiated the deploy to be able to introspect the issue before the deployment system automatically rolls back.
Overall, this approach has made our deployment process more interactive and efficient. Learn more about how we built this integration with Slack in the meetup recording.
Challenge #4: Passing large, sensitive payloads
The final challenge I covered is around passing large, sensitive payloads to workflows and activities. This is primarily a concern for our deployment manifests as they can contain sensitive data and/or hit unexpected limits due to their large scale. As a solution, we decided to encrypt these manifests and save them to object storage. In addition, instead of passing the payload into the workflow or activity, we pass the path to the object as an activity input.
Lessons learned
We learned many lessons throughout the process of building our own deployment system with Temporal. In particular:
- Versioning is important as you roll out changes to workflows. It’s especially important for us as we frequently query closed workflows and store results for a month. Versioning helps us ensure we don’t break the replay of any changes when querying the status of each workflow.
- Needing to think about how the size of our workflows will evolve over time in order to avoid hitting workflow size limits.
What’s next for Chronosphere and Temporal?
Temporal has enabled Chronosphere to more safely and reliably automate complex, long-running tasks. It has also enabled us to easily reuse common activities across different types of workflows. For example, the helper that pauses a workflow if an alert fires can be used by our deployment system and capacity tooling with just a few lines of code. This empowers engineers across different teams to ship features quickly while meeting our rigorous standards for safety and customer trust.
Going forward, we plan to expand our usage of Temporal in developer-facing workflows, and compose workflows in more interesting ways. For example, our tooling for provisioning a dev instance of the Chronosphere stack requires creating base resources from a developer’s machine, and then calling the deployment system to deploy the services needed. We plan on moving the provisioning process to a workflow, which will trigger the deployment workflow. We also plan to extend our deployment system to coordinate deploys across multiple production regions, as opposed to requiring a developer to start different deploys for each region.
If you’re passionate about developer experience, or interested in helping us more safely deliver Chronosphere to all sorts of environments around the world, we’re hiring!
Chronosphere is the only observability platform that puts you back in control by taming rampant data growth and cloud-native complexity, delivering increased business confidence.


