")

Editor’s Note: This excerpt from the first chapter of the Manning Book Platform Engineering on Kubernetes explores working with a cloud native app in a Kubernetes cluster — covering local vs. remote clusters, core components and resources, and common challenges — using real-world examples. To read the entire chapter, download the book here.
Cloud native challenges
In contrast to a monolithic application, which will go down entirely if something goes wrong, cloud native applications shouldn’t crash if a service goes down. Cloud native applications are designed for failure and should keep providing valuable functionality in the case of errors.
A degraded service while fixing problems is better than having no access to the application. In this section, you will change some of the service configurations in Kubernetes to understand how the application will behave in different situations.
In some cases, application/service developers will need to make sure that they build their services to be resilient, and Kubernetes or the infrastructure will solve some concerns.
This article covers some of the most common challenges associated with cloud native applications. I find it useful to know what are the things that are going to go wrong in advance rather than when I am already building and delivering the application.
Planning for cloud native challenges
This following is not an extensive list; it is just the beginning to make sure that you don’t get stuck with problems that are widely known. The following sections will exemplify and highlight these challenges with the Conference application:
- Downtime is not allowed: If you are building and running a cloud native application on top of Kubernetes, and you are still suffering from application downtime, then you are not capitalizing on the advantages of the technology stack that you are using.
- Service’s built-in resiliency: Downstream services will go down, and you need to ensure that your services are prepared for that. Kubernetes helps with dynamic service discovery, but that is not enough for your application to be resilient.
- Dealing with the application state is not trivial: We must understand each service’s infrastructural requirements to allow Kubernetes to scale up and down our services efficiently.
- Inconsistent data: A common problem of working with distributed applications is that data is not stored in a single place and tends to be distributed. The application will need to be ready to deal with cases where different services have different views of the state of the world.
- Understanding how the application is working (monitoring, tracing, and telemetry): Having a clear understanding of how the application is performing and that it is doing what it is supposed to be doing is essential for quickly finding problems when things go wrong.
- Application security and identity management: Dealing with users and security is always an afterthought. For distributed applications, having these aspects clearly documented and implemented early on will help you to refine the application requirements by defining “who can do what and when.”
Let’s start with the first of the challenges: Downtime is not allowed.
Downtime is not allowed
When using Kubernetes, we can easily scale up and down our services’ replicas. This is a great feature when your services were designed based on the assumption that the platform will scale them by creating new copies of the containers running the service.
So, what happens when the service is not ready to handle replication or when no replicas are available for a given service?
Effective Platform Engineering
Platform engineering is more than just a technical discipline. It’s a way to unlock creativity and collaboration across your teams. Start building effective platform engineering strategies today.
How to scale replicas with kubectl
Let’s scale up the Frontend service to have two replicas running. To achieve this, you can run the following command:
kubectl scale --replicas=2 deployments/conference-frontend-deployment
If one of the replicas stops running or breaks for any reason, Kubernetes will try to start another one to ensure that two replicas are up all the time. The figure below shows two Frontend replicas serving traffic to the user.
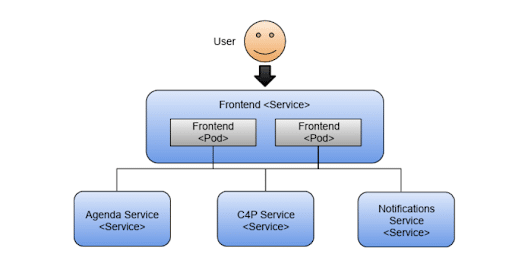
By having two replicas of the Frontend container running, we allow the application to tolerate failures and also to increase the number of concurrent requests that the application can handle.
Kubernetes self-healing in action (ReplicaSet behavior)
You can quickly try this self-healing feature of Kubernetes by killing one of the two pods of the application Frontend. You can do this by running the following commands, as shown in listings 1 and 2.
See Listing 1 below to check that the two replicas are up and running.

Now, copy one of the two Pods Id and delete it.
> kubectl delete pod conference-frontend-deployment-c46dbbb9-ltrgs
Then list the pods again, as shown in Listing 2 below: a new replica is automatically created as soon as one goes down.
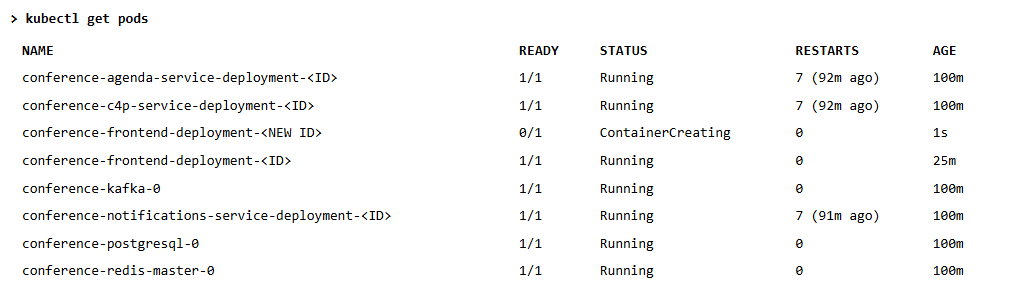
You can see how Kubernetes (the ReplicaSet, more specifically) immediately creates a new pod when it detects only one running. While this new pod is being created and started, you have a single replica answering your requests until the second one is up and running. This mechanism ensures that at least two replicas answer your users’ requests.
The figure below shows that the application still works, because we still have one pod serving requests.
What happens when you only have a single replica?
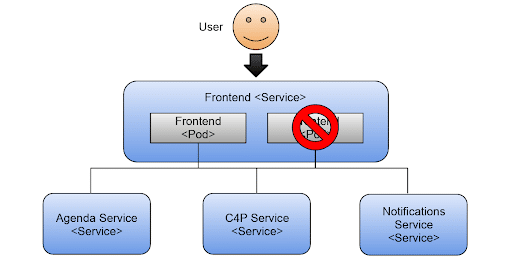
If you have a single replica and kill the running pod, you will have downtime in your application until the new container is created and ready to serve requests.
You can revert to a single replica with the following:
> kubectl scale --replicas=1 deployments/conference-frontend-deployment
Go ahead and try this out. Delete only the replica available for the Frontend pod:
> kubectl delete pod
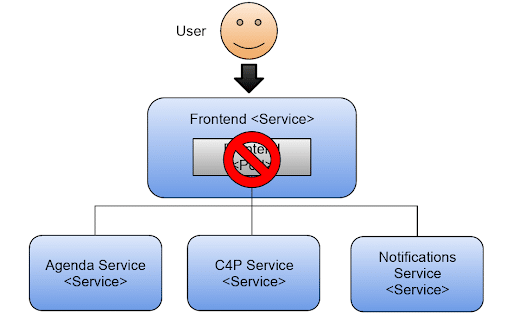
This figure shows the application is not working anymore because there are no Frontend pods to serve incoming requests from users.
How to reproduce and recognize a 503 from the Ingress controller
After killing the pod, try to access the application by refreshing your browser (http:// localhost). You should see “503 Service Temporarily Unavailable” in your browser, because the Ingress controller (not shown in the previous figure for simplicity) cannot find a replica running behind the Frontend service.
If you wait for a bit, you will see the application come back up.
The figure below shows the 503 “Service Temporarily Unavailable” being returned by the NGINX Ingress controller component that was in charge of routing traffic to the Frontend service.

With a single replica being restarted, there is no backup to answer user requests
This error message is quite tricky, because the application takes about a second to get restarted and to be fully functional, so if you didn’t manage to see it, you can try to downscale the frontend service to zero replicas with kubectl scale --replicas=0 deployments/conference-frontend-deployment to simulate downtime.
This behavior is expected because the Frontend service is a user-facing service. If it goes down, users will not be able to access any functionality, so having multiple replicas is recommended.
Best practices for user-facing services on Kubernetes
From this perspective, the Frontend service is the most important service of the entire application, since our primary goal for our applications is to avoid downtime.
In summary, pay special attention to user-facing servicesexposed outside of your cluster. Whether they are user interfaces or just APIs, ensure you have as many replicas as needed to deal with incoming requests. Having a single replica should be avoided for most use cases besides development.
Frequently Asked Questions
Why is downtime “not allowed” in cloud native Kubernetes apps?
Kubernetes avoids downtime by using multiple replicas—if one fails, others keep serving users and Kubernetes quickly replaces the broken pod. This self-healing prevents single failures from stopping the whole app.
What happens if the frontend service has only one replica and the pod fails?
- App will be unavailable until a new pod is started
- Users see a “503 Service Temporarily Unavailable” error
- Recovery is automatic, but downtime occurs while restarting.
How does scaling frontend replicas help prevent downtime?
With multiple frontend replicas, Kubernetes ensures at least one pod is always available to handle requests even during failures. Self-healing keeps service interruptions brief and user access continuous.
Why should you avoid a single replica for user-facing services?
Single replica leads to downtime if the pod restarts or fails—no backup exists. Multiple replicas are crucial for uninterrupted production service. One replica is only recommended for development, not production.
Download the ebook to explore what happens if the other services go down.
A Buyer’s Guide to Modern Observability for Cloud Native
Dive deeper into cloud native observability—download our buyer’s guide to modern observability.


