")




Editor’s Note: This article is an excerpt from The Manning Book: Effective Platform Engineering. This book explores how Platform Engineering practices can dramatically improve operations, and this specific excerpt focuses on design choices to consider as you begin scoping out your software-defined platform. To read the complete section in its entirety, you can skip ahead and download the entire book.
As you begin to design your software-defined platform, you may start to struggle with design choices.
Is the X tool or Y tool better for security scans? Should the teams be managed in a centralized API or GitHub? Should we use an open-source tool or work with a vendor? Is using infrastructure-as-Code to create our services and resources appropriate, or should we use a managed infrastructure service? You could even think about the familiarity of the developers with architecture choices, and how difficult it could be to learn them.
All of these questions are good ones, and they have different answers in different contexts. The most important thing to remember is something we discussed in [previous chapters]. When you have difficult technology decisions that can reach the same result, we should always pick the one that is easier to change in the future.
This principle also applies to the architecture of our platform. When we’re making design choices about our Engineering Platform, we can’t possibly know how the platform will be used a year from now. So, all we can do is make design choices that are flexible and malleable.
Backlog management for incremental design
As we introduce the concepts of platform engineering to the business, the ideas start flowing. Everyone in Product, Ops, Marketing, and leadership has an idea for the platform that we “simply must do.” It’s good to capture those high-level ideas as large buckets, ideas, or epics if you use some form of iteration management tooling.
But as we capture the backlog and ideas from our stakeholders and leaders, the team begins to get stuck. It’s hard to imagine if we’ll need a platform UI for the dev teams because we don’t have any dev teams using the platform yet! We might be able to get some nods of approval when we bring up the idea of a CLI to talk to the APIs, but until users get hands-on, it’s just an assumption.
In practice, master plans fail—because they create totalitarian order, not organic order. They are too rigid; they cannot easily adapt to the natural and unpredictable changes that inevitably arise in the life of a community. As these changes occur…the master plan becomes obsolete
We don’t want to implement massively complex features that nobody ends up using. Getting the platform to a minimum viable usability allows us to quickly switch gears into a process of software development that enables the platform to grow based on the real needs of its users.
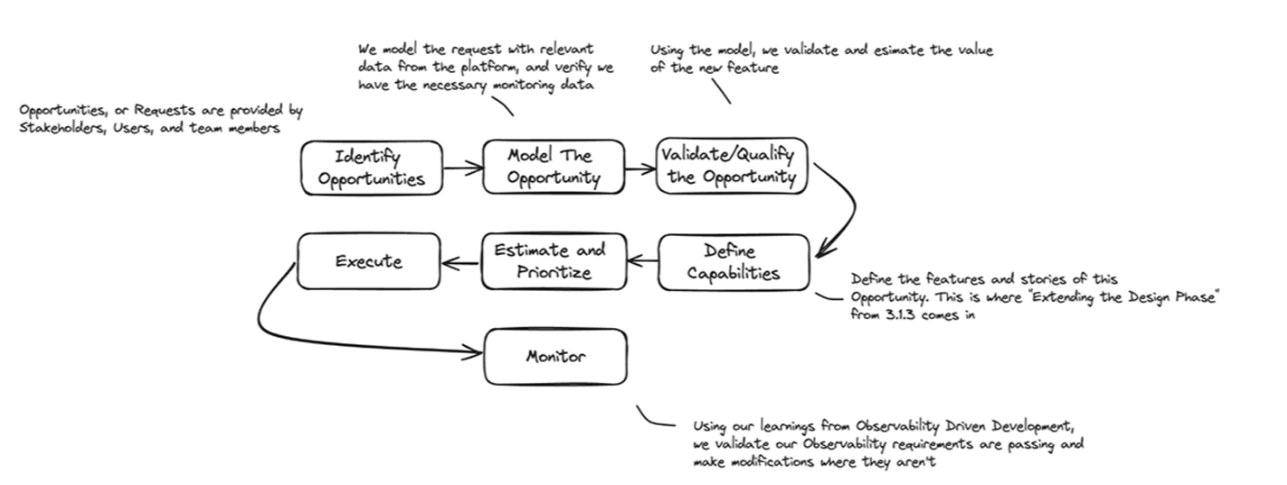
The figure above illustrates the flow of iteration in platform development. Using a flow during iteration will focus development on how the short-term lifecycle fits into the bigger picture.
When you try to look too far ahead into your platform’s life, you forget to focus on the short-term lifecycle of the work that needs to be done in the immediate future. Instead of concentrating on the work that needs to be done within the next 1-4 weeks, you can ensure that the work being done, and about to be done, is identified, modeled, validated, and properly defined.
This provides less confusing and more consistent execution and measurement of your outcomes, allowing you to pivot and evolve your platform much more fluidly.
We also highlight again the importance of monitoring data in this workflow. Note how we refer back to our learnings from observability-driven development at multiple stages in this process.
Model, validate, define: A short-cycle loop
At step 2, “Model the Opportunity,” we are modeling the requested change and validating that we have the necessary data to do so and the necessary data to build the feature. And as we proceed to define the new capability, we are making sure to build changes for new data points so that our platform’s new capability can be monitored and alerted on properly.
Going back to our example of the traffic blocking alerts, if we don’t account for making sure we are collecting network data during our “Define” phase, we’ll be missing the necessary tests and infrastructure to capture these data points, rendering our tests useless.
Let’s say a stakeholder comes in and says, “My team needs a user interface to push deployments to the platform.” Our PETech team has some debate about this once it’s time to prioritize it for the platform. Some members think that very few engineers will use it.
Following our incremental change process, let’s see if we can answer some of these debates. From stage 1, we have already identified the opportunity, but let’s put it into words:
As a developer, I need a User Interface to push deployments to the production cluster.
Great, now let’s model and then validate it. Given that this is a user experience feature and not something we can directly validate with monitoring data, we’ll need to model this feature with data given to us by our users.
As a team, we assume that most of the developers will prefer to use the CLI in a deployment pipeline. But we need data to model this assumption and validate it.
Surveying developers: CLI vs. GUI adoption
So, we’ll want to start with a small 2-question User Survey and send it out to the engineering group:
Question 1 (select multiple): In your day-to-day role, do you prefer to use:
- CLIs
- APIs
- GUIs
- All of the Above
- Other
Question 2: If given a choice between the current CLI in a pipeline and a click-to- deploy GUI, which would you deploy to the platform with?
- CLI
- GUI
We send this out as a simple Slackbot 2-part question, making it as easy for our engineers to answer it and return to their jobs.
We don’t want to inundate our users with lengthy or wordy surveys; it’s best to model these new capabilities with questions that are most likely to get as many responses as possible. Keeping it short ensures we’ll at least get a majority (50% or higher) response rate.
Our results come in, and we get:
This table shows the responses to the two questions that were posed above.
Surprisingly, there are more users than we expected who want to use a GUI to deploy to the platform! Had we just used our assumptions and not modeled and validated them, we never would have developed this feature, leaving 40% of our users using a set of features they would prefer to do in a different interface.
This model and validation outline the importance of due diligence regarding new features and opportunities for the platform.
We also reinforced the importance of simplicity. In our experience building platforms, we’ve noticed that when we start complex dialogues, open conversations, or lengthy RFCs, the engagement is a meager overall percentage of the developer population.
It’s important to remember that every individual in the engineering organization has a role to perform and daily duties to focus on. By making our survey short, sweet, and in the medium our teams are already using (say, a 2-part in-channel Slack question), we reach a much broader audience and get a proper validation of our assumptions.
Measuring UX and adoption targets
Now that we know we will build this GUI for our users, what sort of data do we need to think about in our Define stage?
In earlier chapters, we learned that we want to think about what data we require to drive functional automated tests for the platform. Given this is a UI for our development teams, we’ll want to ensure they are having an excellent overall experience, including latency, low error percentages, and fast page load times.
We’ll also want to write tests and automation that ensure we are properly collecting this data; for example, error percentages could be perceived as low if we aren’t collecting the proper stream of errors.
As we move on to the future stages of the iteration, including execution and monitoring, we want to look for a similar percentage of adoption as we saw in our survey.
If we had 40% of users saying they would like to use the GUI of our platform, this is our target adoption percentage as we roll out the new feature. We can write observability data to track this, and if we don’t meet it, we can do follow-ups with our users to find out what’s going on, making changes to fit their needs and to meet our acceptable adoption percentage.
You might now be asking how to spot the opportunities required to build a platform. To learn how, keep reading, download the entire book.
Frequently Asked Questions
What is an evolutionary platform architecture?
A platform approach that favors reversible choices and short, telemetry-rich iterations over big-bang designs.
How do I prioritize a platform backlog?
Treat items as hypotheses: model, validate with tiny data, estimate impact/effort/risk, then schedule with strict WIP limits.
What fitness functions should a platform use?
Examples: adoption %, p95 task time, change-failure rate, MTTR, error budgets, % self-service without human help.
How do I de-risk building a deployment GUI?
Survey preferences, instrument usage, set adoption targets from the survey baseline, and compare post-launch behavior.
What principle should guide hard platform technology choices?
When experiencing difficult technology decisions that can reach the same result, always pick the one that is easier to change in the future. This principle also applies to the platform’s architecture.
Why aim for minimum viable usability before big features?
Don’t implement massively complex features that nobody ends up using. Getting the platform to a minimum viable usability makes it easier (and faster) to switch gears into a process of software development that enables the platform to grow based on the real needs of its users.
Why define telemetry before building capabilities?
Defining telemetry before building capabilities ensures that all outcomes can be validated and measured from the start, allowing teams to track adoption, detect issues, and make evidence-based improvements as the platform evolves. Without early telemetry signals like latency and errors, features cannot be properly tested, monitored, or improved to meet user needs.
Effective Platform Engineering
Platform engineering isn’t just technical—it unlocks team creativity and collaboration. Learn how to build powerful, sustainable, easy-to-use platforms.


