")

Introducing Timeslice SLOs: A different way to track system health
What happens when five minutes of downtime blows your entire Service Level Objectives (SLO) for the month?
If you’ve ever watched a sudden spike in traffic torch your error budget in a flash, despite the rest of your service running smoothly, then you’ve seen one of the side-effects of event-based SLIs. They treat every request the same, whether it’s 2 a.m. on a holiday or a production rollout during peak hours.
That’s where Timeslice SLOs (aka time-based SLIs) come in. And we’re excited to announce they’re now available in the Chronosphere observability platform as an addition to our recently introduced Chronosphere SLOs capability that transforms how engineering teams create, manage, and use Service Level Objectives.
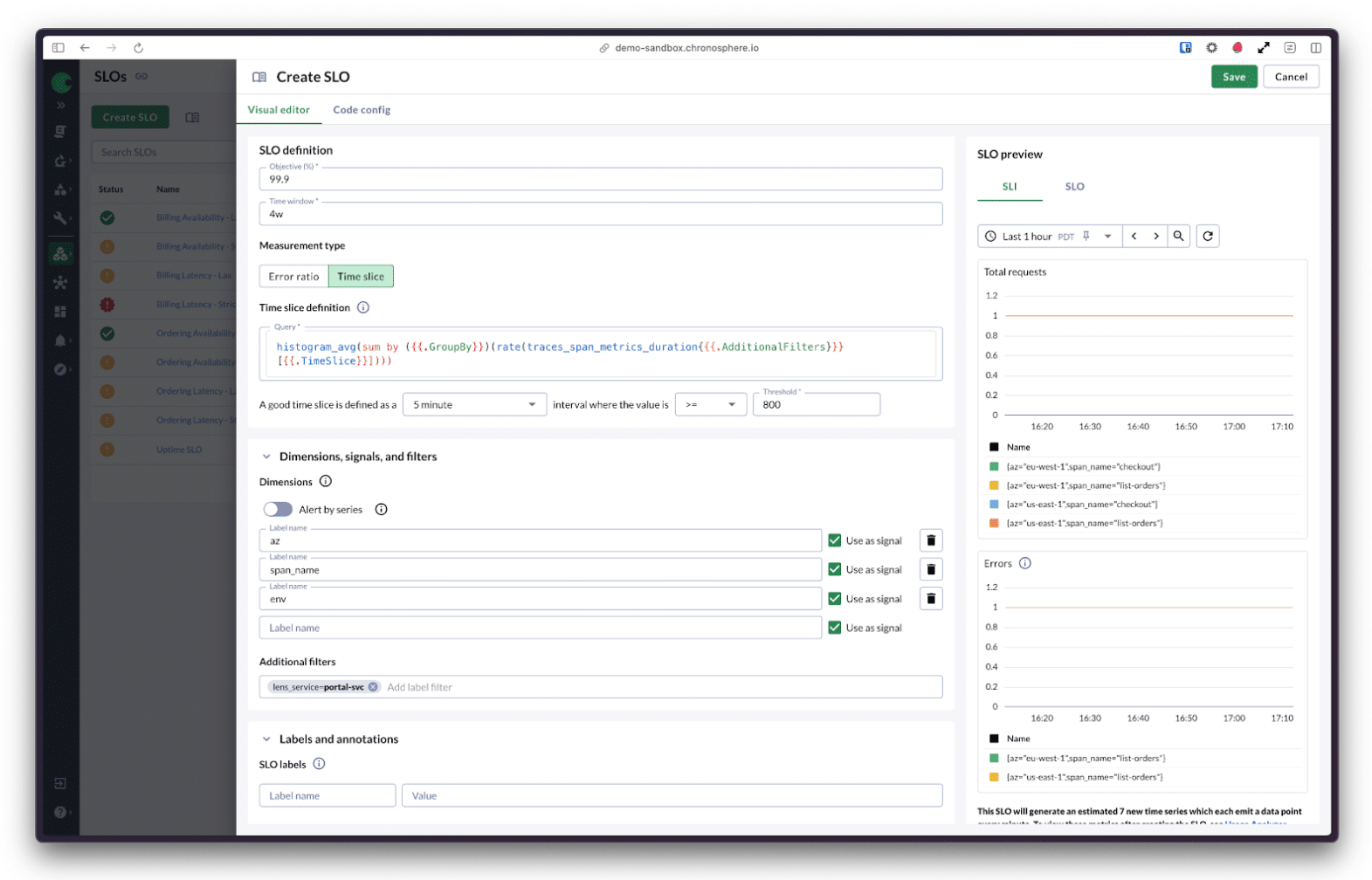
Okay, so what is a Timeslice SLO?
Imagine slicing your monitoring window (say, 28 days) into tiny pieces like 5-minute chunks. In each slice, you ask a simple question: Was the service level indicator (SLI) healthy during this time? If yes, it’s a “good” slice of time. If no, then it’s “bad.” Your SLO then becomes the percentage of good slices over total slices.
That means every slice of time gets equal weight, whether one request came through or 10,000.
“Time-based SLIs are not sensitive to the amount of load… They’re more forgiving of failures due to spikes.”
Event-based vs Time-based: What’s the difference?
Event-based SLIs measure the number of successful events (like API requests) divided by the total number of events. If 10,000 requests fail in five minutes, your budget takes a massive hit, even if those five minutes were a fluke.
SLI = (good events/valid events) x 100 for the 4week or 28 day window
Time-based (Timeslice) SLIs, on the other hand, treat time as the unit of measure. They ask: How many units of time were good? So five bad minutes = five burned slices, whether they held 10 or 10,000 requests.
SLI = (good time/valid time) x 100 for the 4week or 28 day window
Or
SLI = (number of good timeslices/total number of timeslices in the window) x 100
Interestingly, in a standard 28 day time window there are:
- 40,320 x 1-minute time slices
- 8,064 x 5-minute time slices
Both 1- and 5-minute slicing are options in the if you have a granularity preference.
Event-based SLOs and Timeslice SLOs Comparison
Real-world application
Picture this: You run an e-commerce platform. A flash sale launches, and your traffic jumps from 500 to 10,000 checkouts in 5 minutes. A service hiccup means every one of those fails.
With an event-based SLO, your entire error budget is toast. But with a Timeslice SLO, that same issue counts as just five bad minutes out of 8,000+. That gives your team breathing room to respond without worrying about missing your SLO instantly.
Learn more about Chronosphere SLOs
Easily create and manage SLOs and Error Budgets in containerized, microservices environments.
Strategic insight: Business impact you can trust
When SLOs fail to reflect actual impact, teams lose confidence in the observability platform. Overly sensitive metrics can derail roadmaps, trigger unnecessary postmortems, and create alert fatigue.
Timeslice SLOs restore balance by aligning measurement with human intuition. Five bad minutes shouldn’t dictate four weeks of defensive planning unless it truly reflects customer pain.
Here’s what this unlocks:
- Smarter error budgeting, less prone to overreaction.
- Reduced alert noise, especially for services with inconsistent load.
- More precise post-incident analysis, pinpointing time windows instead of raw error counts.
Why this matters for SREs and observability teams
Let’s say you’re running a service. You define a Timeslice SLO that monitors response latency using a 5-minute interval. If the latency average goes over 800ms, that time slice is “bad.” Over a 4-week window (8,064 slices), you can pinpoint exactly when things went sideways and with Chronosphere, you can identify where it happened by Availability Zone, span name, environment, etc.
Here’s why this changes the game:
- You won’t blow your error budget in one short incident.
- You get visibility into health across consistent, equal-time chunks.
- You don’t need perfectly uniform traffic to trust your numbers.
- You can finally align burn rate alerting with business hours.
This is super handy for a number of use cases – especially when traffic spikes are unfairly wrecking your error budget.
From false urgency to focus: Adopt Timeslice SLOs
Timeslice SLOs offer a smarter, more resilient way to measure reliability. By shifting focus from raw event counts to periods of system health, you get a clearer view of what actually matters — consistent performance over time. Whether you’re migrating from Datadog, tuning alerting strategies, or just tired of false urgency, Timeslice SLOs in Chronosphere give you the flexibility, fairness, and insight your teams need to stay focused on building, not babysitting.
Frequently Asked Questions
What are Timeslice SLOs?
Timeslice SLOs are a type of service level objective that measures system reliability based on chunks of time (like 1-minute or 5-minute intervals) rather than individual requests. Instead of asking “how many requests failed?”, they ask “was this time slice good or bad?”
You then calculate your SLO based on the percentage of good time slices over a set window (like 28 days). This helps teams track service health more evenly, especially when traffic is bursty or inconsistent.
What’s the difference between an event-based SLI and a time-based SLI?
Event-based SLIs measure the ratio of successful events (like HTTP requests or transactions) to total events, which can be great when every request counts. But they can be overly sensitive during high-traffic spikes. Time-based SLIs (used in Timeslice SLOs) measure how many units of time your system was “good,” giving each time slice equal weight. That means a short burst of failures won’t burn your whole error budget, making time-based SLIs better for services with variable or uneven traffic.
When should I choose a Timeslice SLO over an event-based SLO?
Use Timeslice SLOs when uptime or overall service behavior over time matters more than individual request counts, for example, monitoring latency, availability, or steady-state systems where occasional spikes don’t reflect systemic failure. Event-based SLOs are better for critical paths where every request matters, like checkout flows or payment APIs.
Can Timeslice SLOs help reduce alert fatigue?
Yes. Because Timeslice SLOs only flag “bad” slices instead of reacting to sudden event spikes, they’re less likely to trigger noisy or unnecessary alerts especially during off-hours or low-traffic periods. This leads to more meaningful on-call signals and fewer false positives.
Do Timeslice SLOs support different environments or dimensions?
Definitely. You can define Timeslice SLOs by environment, availability zone, span name, and more using grouping dimensions (the different facets or categories that define a learning outcome or service performance).
Chronosphere dynamically tracks each signal separately, so new service variants automatically get their own error budgets.
How does error budgeting work differently with Timeslice SLOs?
Instead of counting failed requests, Timeslice SLOs count failed time slices. That means one bad slice equals one unit of budget burned. no matter the traffic during that slice. This helps teams plan more effectively and avoid disproportionate penalties during short-lived incidents.
What are the ways that I can create Timeslice SLOs within Chronosphere?
Timeslice SLOs can be created via UI, API, CLI, or Terraform.
Are Timeslice SLOs backward compatible with my existing SLOs?
Timeslice SLOs live alongside traditional SLOs. You can migrate selectively.
Can I use Timeslice SLOs with alerting?
Yes! Alerting is fully supported. Just toggle it on during setup.
Do I need uniform traffic to use Timeslice SLOs?
Nope. That’s one of the main advantages. Timeslice SLOs work great even with irregular traffic patterns.
How do Chronosphere Timeslice SLOs compare to Datadog?
Chronosphere now supports Timeslice SLOs natively, and we’ve optimized for Datadog SLO migration compatibility.
Manning Book: Effective Platform Engineering
Learn actionable insights and techniques to help you design platforms that are powerful, sustainable, and easy to use.


