

Summary
In a recent webinar, Scaling Prometheus: Frameworks for High-Volume Metrics, our team explored why the traditional Prometheus “monolith” often fails as your environment grows. Scaling requires moving beyond simply adding hardware to address specific bottlenecks in query performance, data retention, and metric volume.
In this article, we’ll walk through the strategies discussed in the webinar—from internal optimizations to federation—to help observability managers scale Prometheus. You can watch the full webinar recording here for a deeper dive into these frameworks and live configuration examples.
Recognizing the limits of the Prometheus monolith
The standard Prometheus architecture was originally designed as a single-binary monolith. In this model, one instance handles service discovery, scraping, storage (via a time-series database or “TSDB”), and rule evaluation. As your environment grows, this all-in-one approach becomes an architectural bottleneck because these functions compete for the same CPU and memory resources.
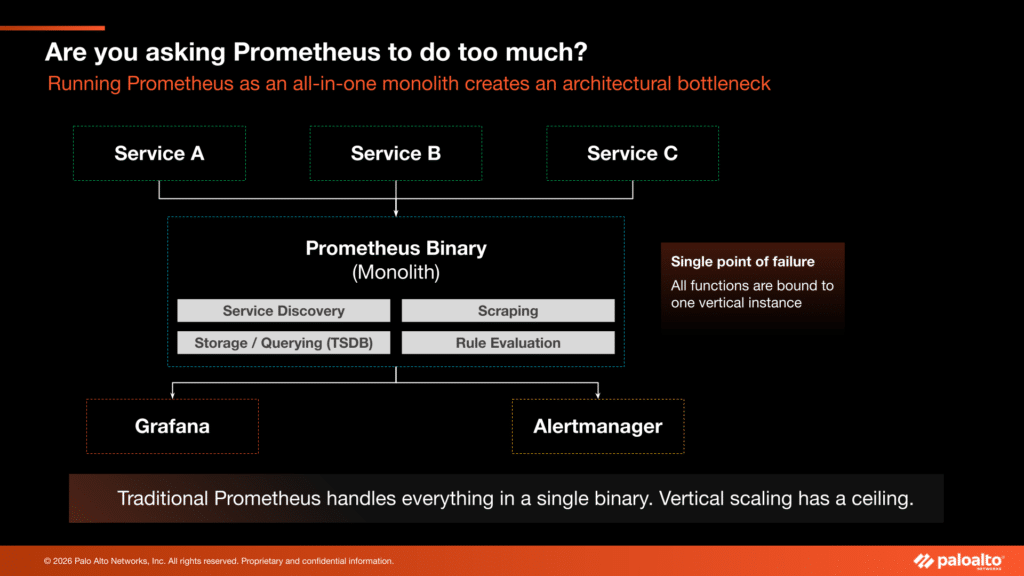
You will likely recognize the limits of the monolith when you encounter the following scaling pains:
4 scaling pains of Prometheus
1. Query performance
Dashboards and alert rule evaluations consistently time out because query load competes with ingestion for resources. Poor query performance typically boils down to the number of time series you ask Prometheus to fetch.
2. Discovery and scraping
Service discovery becomes slow or unreliable, leading to gaps in data (scrapes missing their intervals). When you have gaps in your data, you increase the likelihood of missing a production incident and/or losing your engineers trust in the metrics system.
3. Long-term retention
Prometheus was not built to be a long-term metrics store. Storing and querying historical data becomes prohibitively resource-intensive for a single local disk. This shows up for your users with slow performance.
4. Metric volume
The cause of this is often that users start adding more data as they experience success with Prometheus. You can unintentionally add verbose metrics (e.g. Envoy metrics), which causes your instance to blow up. The total number of active time series exceeds the memory capacity of the instance, leading to Out-of-Memory (OOM) crashes and “head block” saturation.
How to solve the scaling pains of Prometheus
Now that you understand the symptoms of Prometheus scaling challenges, let’s walk through four ways that you can solve them.
Approach #1: Throw hardware at the problem
The most immediate response to a struggling Prometheus instance is vertical scaling—giving the binary more RAM and CPU. Because Prometheus keeps the “head block” (the most recent data) in memory, increasing RAM allows you to handle a higher number of active time series and larger chunks of index data.
While this is the easiest path, it has a ceiling. You should think about this approach as a first step—one that buys you more time to pursue other optimizations. That’s because even with a 64-core machine, a single instance can only scale so far before underlying lock contention or the sheer time required for memory-intensive compactions becomes the new bottleneck.
Scaling the hardware will certainly enable you to store more time series. But, it doesn’t necessarily mean your Prometheus instance will return queries faster—you need to pursue other optimization to improve the user experience.
Approach #2: Introduce pre-aggregation and query caching
When query performance degrades, you can find relief by shifting the computational cost from the “read” side to the “write” side. The primary tool for this is recording rules. Let’s say you have a dashboard that calculates a 5-minute rate of a counter across 10,000 pods. That calculation is expensive to run every time the dashboard refreshes.
A recording rule performs that calculation at ingestion and saves the result as a new time series. This turns a complex, multi-series PromQL expression into a simple “fetch” of a single pre-calculated metric. In other words, it takes what was historically a “foreground” task and runs it in the “background.”
If your team isn’t waiting for queries to return, they’ll be happier users.
As you add recording rules, it is critical to strike a balance—not too few, not too many. Recording rules do increase the baseline load on the system. So if you create too many, it will cause other issues.
To further protect the TSDB, you can introduce a caching layer like PromCache or Trickster. These tools act as a reverse proxy that caches time-series data. It is particularly effective because it uses “delta-proxying”: if a dashboard requests the last 6 hours of data and then refreshes a minute later, it will only fetch the new 1 minute of data from Prometheus and merge it with the cached results. This dramatically reduces the repetitive query load on your backend.
Approach #3: Offloading discovery and scraping with Agent Mode and OTel
In high-churn environments, such as Kubernetes clusters where pods frequently restart, the overhead of service discovery and scraping can overwhelm a standard Prometheus instance. You can decouple these tasks using Prometheus Agent Mode or the OpenTelemetry (OTel) Collector.
Prometheus Agent Mode
Using Prometheus Agent Mode enables you to use the binary you already know and love as at the collection level. Agent Mode decouples collection from local storage and alerting, running Prometheus in a distributed fashion. It performs discovery and scraping and streams the data via Remote Write to a central location. Because it doesn’t need to maintain a local TSDB or perform compactions, it uses significantly less memory and CPU.
There is certainly a tradeoff with Prometheus Agent Mode. On the plus side, Prometheus Agent Mode is a smaller change, versus adopting the OTel Collector. Again, you’re extending the binary you already use. However, you need to manage scraping rules to ensure you’re not collecting duplicate data—this can add overhead, especially at scale. If you want maximum scalability, it’s beneficial to adopt the OTel Collector instead.
OTel Collector & Target Allocator
In this setup, you use multiple OTel Collectors—each of which is responsible for scraping different parts of the cluster to ensure you don’t duplicate data. In this configuration, OpenTelemetry handles a lot of the orchestration involved in collection. There are three parts to this setup:
- Centralized discovery: The Target Allocator handles discovery of new resources and data in a centralized manner.
- Collector registration: When you need to scale collection, OTel Collector pods spin up and register themselves to the Target Allocator. The Target Allocator keeps a list of all active collectors.
- Target sharding: The Target Allocator works off its list of collectors and allocates jobs accordingly. If one collector becomes overloaded, the Target Allocator can redistribute the “targets” (the services being scraped) to other collectors, ensuring high availability and balanced load.
Approach #4: Introducing federation and remote storage
The final approach involves moving toward a distributed architecture.
Federation
The final approach involves moving toward a distributed architecture. Federation effectively sub-divides your monolithic Prometheus workload into edge instances and a central instance.
It allows you to maintain “leaf” Prometheus instances in different clusters or regions that handle local scraping and short-term alerting. A “global” Prometheus server then scrapes the leaf instances to provide a unified, but aggregated view across the entire infrastructure. If you want to monitor what’s happening in your different systems at a granular level, you go to the edge instance to see all the details.
There is some overhead with federation. You’ll need to go to determine how to subdivide workloads and make sure they’re scoped appropriately. Additionally, you’re in charge of curating the data going to the global view.
Remote storage
For true long-term retention (weeks or months) and high-volume stability (tens of millions of series), the standard is to move data into specialized remote storage backends like the CNCF-graduated project, Thanos.
Thanos is designed to store data in object storage, which is cheaper and more scalable than local disk. They also separate the “querier” from the “ingester,” allowing you to scale your query capacity independently of your data ingestion. With these tools, you can have very performant access going back over years.
Additionally, remote storage backends are designed to work over multiple Prometheus instances—exactly what you’re running with Federation. It effectively alleviates the overhead I described above. So, it makes sense to adopt these solutions in tandem.
Choosing your scaling path
Scaling is rarely a single event; it is a series of trade-offs. You might start with vertical scaling to solve an immediate crisis, implement recording rules to improve user experience, and eventually adopt Agent Mode or remote storage as your environment matures. With these four approaches, observability managers can systematically address bottlenecks and ensure their monitoring remains as resilient as the services it tracks.


