")

Editor’s Note: This article is an excerpt from The Manning book Logging Best Practices: A Practical Guide to Cloud Native Logging. This book provides the practical framework you need to transform logging from a reactive debugging tool into a proactive competitive advantage, and can be downloaded to read in its entirety here.
Applying structure to log messages makes the information found in them actionable because the logic processing the logs can derive meaning from the data.
Suppose we experienced an error with a database connection, which produced a structured log event. It wouldn’t be hard to implement a parser expression to retrieve the database connector error code and the database details. This could be done by Fluentd, and therefore, a signal could be sent to the relevant database team.
The log analytics tool could act on the same data, but the alert would be later, and more problems could have occurred. But the log analytics could help us by examining histories to determine if the problem was reoccurring, and, if so, at what frequency, and if there was a commonality to the nodes(s) registering the problem.
Logging Structure
The structuring of logs goes further than that, as we need to also have a structure around details such as timestamps, log levels, location, thread IDs, and so on, that help provide context. There are some industry-recognized formats. The figure below provides details of the ones typically associated with application logic.
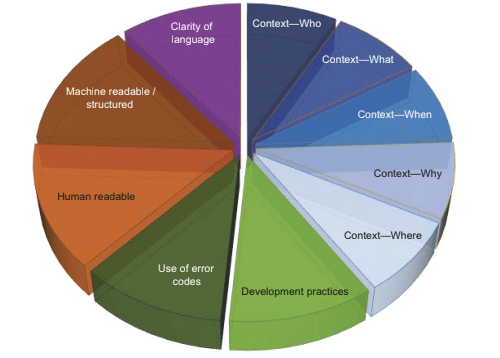
The aspects that, when combined, will provide excellent log events and robust mechanisms to use as needed
Making log entries ready for application shipping into action
As part of a development team, your server-based application reaches the point of being sufficiently well featured. The beta and early adopter customers are successfully using your software. The management team recognizes that to provide cost-effective support, documentation needs to be provided to avoid frustrated system administrators and unnecessary support calls.
Also, good support documentation will help prevent support requests from coming back to the development team. You’ve been asked to identify what needs to be achieved and how long it is likely to take to implement, as well as if there is anything that can be done to minimize the time before sales can ramp up activities.
ANSWER
There are a great many things that could be done, and there is no single correct answer, except to build on what this chapter has discussed. When estimating such a task, the simplest thing is to search the currently active code base for log events and record the type of event. Then estimate the effort to evaluate the log events against the different factors illustrated in the image above.
Being pragmatic, if the estimates are squeezed, it is best to adopt a top-down approach, as illustrated below.
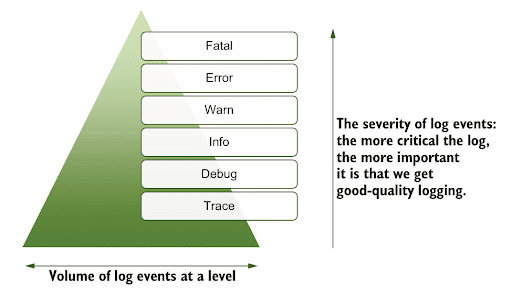
The most critical logs require the best logging practices
With the estimated effort of working through the code checking and amending the log events, you also need to estimate the effort to produce the supporting documentation. If you provide the documentation through channels such as a website rather than embedding it in the code, the software release can start before this documentation is complete.
Obviously, there is a temptation to not complete this task and focus on the following product version with this approach. Conversely, not addressing this will directly impact the number of support calls, including those that get escalated back to the developers, even in a more traditional organizational arrangement.
Use frameworks if you can
Most programming languages provide logging frameworks, either as part of the base language or as libraries. Adopting a framework for logging can help in several ways to improve your logging. Potential benefits include the following:
- Consistency in the log data– including:
- Consistency in log levels
- Structure of log entries
- Additional contextual information is managed for you
(e.g., if the framework understands OpenTracing,
it can pull trace context values). - The framework can allow us to control what is looked at
through configuration, making it easier to determine how
much or how little logging is needed. - Importantly, when logging in a containerized environment,
we can save a lot of effort if we don’t have to reparse
text outputs to apply context and meaning. This saves
processing power, and many log frameworks allow us to
direct output mechanisms that can help avoid this overhead.
Using one of the many third-party or language native solutions is preferable, as they will be tried and true. Even a simplified piece of your own code that helps drive consistency is valuable.
The mission-critical systems I started my career working on fell into this category. If you go down the route of using Homebrew, we would strongly recommend adopting one of the industry-standard formats to make ingestion into other tools a lot easier.
Development practices
We’ve seen a number of things we can do to positively improve the situation. But there are some common development practices that can be negative in nature, even if the intent is presented positively.
Rethrowing exceptions
Catching and rethrowing exceptions (the act of having a catch block in code and then using throw statements to raise the exception again) is a bad practice that can have undesirable impacts on logs, given that typically, when an exception is caught, it is logged.
This means if you catch and rethrow an exception, the odds are you’ll end up with multiple log events for the same problem. When it comes to analyzing what is wrong, you’ve increased the workload for determining which log event was the first actual occurrence of a problem and have doubled up on the number of alerts, moving another step closer to a “notification storm.”
Notification or alert storms
Notification or alert storms are something to watch out for if you link your log events to a notification mechanism such as email or Slack. If you keep getting the same error, such as when logic keeps getting stuck in an infinite loop of trying to do something (e.g., writing to a file with no storage space available), then you end up with the same message saturating the notification channel. The net result is that everyone switches off and unsubscribes to notifications; worse still, systems think your application generates spam and it gets blocked. Fortunately, there are techniques for suppressing such scenarios, such as filters in Fluentd or in the logging framework itself. For example, Log4j2 provides a BurstFilter, and Log4Net has an extension that does the same sort of thing.
Using standard exceptions and error structures
My position on using standard exceptions from programming languages is possibly a more contentious point, as I don’t agree entirely with the assertion that standard exceptions should be thrown.
For example, Joshua Bloch’s Effective Java (Addison-Wesley Professional; 3rd edition, 2017) advocates that if you have defensive code, and a value you receive is null (nil in Ruby) but shouldn’t be, then your code should use the language’s own NullPointerException or IllegalArgumentException.
The argument made is that you can benefit from code reuse and that someone reading your API will understand the API more easily. While the reuse consideration may have merit, using a language-predefined exception class because it will lend to the understandable definition is about good naming conventions, not insight into the code.
The real problems come when looking at log events; it becomes tough to determine whether this exception resulted from defensive coding or a potential bug. The difference is that defensive coding points to a possible upstream issue. If someone has put in defensive checks, then the chances are someone considered the possibility of a problem and how to leave things in a recoverable state.
While my example and reference to best practice have focused on Java, the foundation principles apply to languages that support exception frameworks, Python and Ruby being two examples. Other languages, like Go, have error structures and the ability to handle the return of different structure types. So the question begs, what is the answer to this?
Going back to Java for a moment, from my perspective, there is nothing wrong with creating a simple one-line class that extends a base class with a clear, meaningful name (e.g., class IllegalBufferConfigurationException extends IllegalArgumentException).
After all, this is how languages apply inheritance for the native exceptions in Java (e.g., NullPointerException extends class Exception). Ruby’s approximate match is ArgumentError, which extends StandardError, which in turn extends Exception.
If an exception is well named, it will be clear as to why the exception is thrown. It also will tell the reader what specific scenarios are being defended against and what the API caller should or should not be doing.
So when we see a generic exception, like a NullPointerException, we’re likely to be looking at a more fundamental problem and one that has not been considered. If we have considered a problem, we probably know what the remediation might be.
Manning Book: Effective Platform Engineering
Learn actionable insights and techniques to help you design platforms that are powerful, sustainable, and easy to use.
String construction as a reason not to log
When logging, we sometimes need to construct a log message by combining several elements to produce a practical level of information. Casting data to strings and concatenating them together takes a little bit of CPU effort.
Let’s assume for a moment that we’re creating an info-level log message, so there is a chance the log message will get filtered out if someone has set the log filter threshold to a warning. In this situation, the CPU effort constructing the log message is effectively wasted. This has been used as an argument for not bothering implementing logging in the code since the log message construction consumes processing effort for no gain.
This argument attempts to rationalize not investing in evaluating where logging will help implement appropriate code, at least from my perspective. There are technical means by which we can minimize the cost. But perhaps, more importantly, the cost of a small number of CPU cycles compared to the cost of a developer’s time trying to investigate and understand what is going on with someone else’s code does weigh in favor of helping the developer.
I’m not advocating writing grossly inefficient code. Still, the extra costs in compute cycles for having supportable and maintainable code (which includes sensible logging) are far smaller than the money saved in developer effort.
Coming back to the practical technical means to avoid waste, every logging framework I know of provides the means to query the logging level currently set, allowing the code to decide whether there is any value in constructing the logging payload. These are sometimes referred to as “guard” functions and can be applied like this:
Logger.ifDebug {
val myLogMessage = "{\"attribute:\" + aStringValue + \",\" + aArrayOfKeyValues.toJSON + \"}\""
Logger.debug(myLogMessage)
}
Obviously, the precise code will differ based on the framework in use and the language-specific syntax, but you see the point.
Over the last 5 to 10 years, we have seen most mainstream languages develop to support Lambda or lazy execution capabilities. This means we can now write code, so the guard is implicit and if the implicit condition resolves, only then are the subsequent expressions evaluated and executed. For example:
LOGGER.atDebug().log('{"attribute:" + aStringValue + "," + aArrayOfKeyValues.toJSON + "}") The result is negligible compute cost and optimization without losing the existence of the logging code. Add to that the performance improvements seen with compilers, virtual machines, and interpreters. We’re gaining performance When you consider this, we’re seeing more efficiency gains that will far outweigh those from not writing log statements.
Download the ebook to explore how to apply filters to log events, including how to implement the record_transformer, and how to mask elements of log events to maintain data security.
Frequently Asked Questions
Why is structured logging important and how does it make logs actionable?
Structured logging makes information actionable because the logic processing the logs can derive meaning from the data. Take a database connection error, for example, where structured logs enable automatic parser expressions to retrieve error codes and database details, allowing systems like Fluentd to send alerts to relevant teams. Additionally, log analytics can examine histories to determine if problems are recurring, their frequency, and identify commonalities across affected nodes.
What elements should be included in proper log structure and format?
Proper log structure requires more than just message content—it needs structure around details such as timestamps, log levels, location, thread IDs, and so on, that help provide context.
Should I use logging frameworks instead of building custom solutions?
Frameworks are strongly recommended, as they provide consistency in log data and levels, structured log entries, automatic contextual information management (like OpenTracing context), and configuration-based control over logging verbosity. Most importantly, frameworks help avoid reparsing text outputs in containerized environments, saving significant effort. Using one of the many third-party or language native solutions is preferable, as they will be tried and true.
Does logging impact application performance, and how can I minimize the performance cost?
While string construction for logging takes minimal CPU effort, the cost of a small number of CPU cycles compared to the cost of a developer’s time trying to investigate and understand what is going on with someone else’s code does weigh in favor of helping the developer. Modern optimization uses guard functions and lazy execution capabilities where the guard is implicit and, if the implicit condition resolves, only then are the subsequent expressions evaluated and executed.
What are the most dangerous logging anti-patterns to avoid?
- Rethrowing Exceptions: Creates multiple log events for the same problem, making it difficult to identify the actual first occurrence
- Notification/Alert Storms: Infinite loops of the same error saturate notification channels, causing people to unsubscribe or systems to block messages as spam
Both issues can be mitigated through proper exception handling design and implementing filters in logging frameworks
Should I use standard language exceptions or create custom ones for better logging?
Standard exceptions are not advocated because when looking at log events because it becomes tough to determine whether this exception resulted from defensive coding or a potential bug. Instead, create a simple one-line class that extends a base class with a clear, meaningful name like IllegalBufferConfigurationException.
Well-named exceptions clarify why they’re thrown, what scenarios are being defended against, and what API callers should or shouldn’t do.
Manning book: Logging Best Practices
Transform logging from a reactive debugging tool into a proactive competitive advantage


