")

Log data is growing at an explosive rate. Last quarter, Chronosphere surveyed over 127 people responsible for their organization’s observability stack. When asked how much their log data had grown, these folks reported a 250% year-over-year growth on average. Many factors contribute to this surge:
- Cloud migration
- Kubernetes adoption
- The sheer amount of new digital experiences (as the cliche goes, “every company is a software company”)
Considering that none of these drivers are slowing down, log data will continue to explode.
Log data growth leads to untenable costs
Why is this an issue? The most common log management and security information and event management (SIEM) platforms used today were built years ago – when data was a fraction of the volume it is today. These tools charge based on the amount of data you ingest and retain – logging pricing can be anywhere from $2 to $5 per gigabyte. As data grows, so do your log management and SIEM costs.
This wasn’t a major issue when large organizations created tens or hundreds of gigabytes worth of data each day. But today, they’re creating terabytes and soon, petabytes. When you combine current logging pricing models with today’s data volumes, you find that most large organizations are spending seven or eight figures annually. What’s worse is large amounts of this data add little or no value to security and observability teams. However, incumbent providers don’t offer the visibility to help customers understand what’s important, nor the control to fix this issue in a sustainable manner.
As a result, it’s no longer feasible to capture 100% of your logs in a hot, searchable logging backend. Instead, the question many teams are asking is: how do I support my team’s use cases without breaking my budget? In this blog post, I’ll discuss a few practical tips for implementing more cost-effective logging practices.
Tips to cut SIEM and log management costs
1. Reduce storage costs by routing data to multiple backends
As I mentioned above, it’s too expensive to store all your logs in a centralized log management or SIEM tool. These tools are still helpful, especially when you need advanced querying and dashboards for analyzing log data.
However, many teams query large portions of data infrequently. Or, they retain data for compliance only. Often this equates to 30% or more of your log data footprint.
When you move these datasets to new storage targets you can dramatically reduce log management and SIEM costs.
Here’s what this can look like in practice:
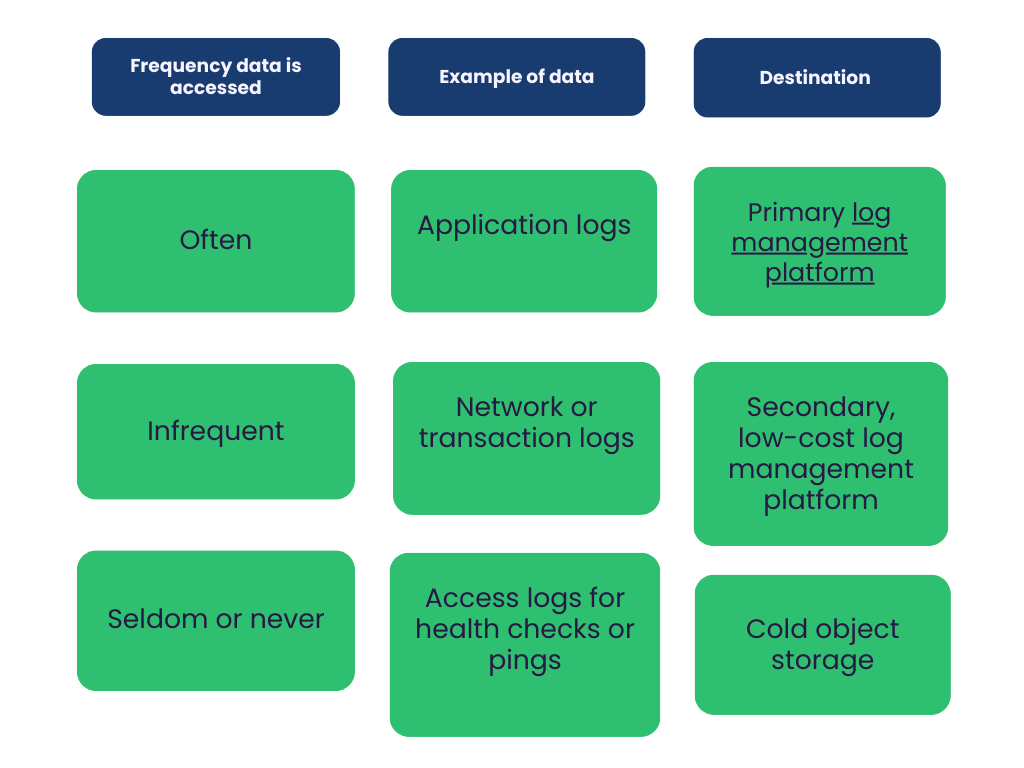
Additionally, you can support long-term compliance by storing log data object storage. Here, you would route a copy of every logline to Amazon S3, Azure Blob, or another low-cost storage target. From there, you can load data back into your centralized log management platform as needed. This tip can also help streamline SIEM log management migration processes.
In some scenarios, you may also want to fork different subsets of data to different platforms based on the content within the log. For example:
- Fields or key/value pairs within your logs
- Metadata added as tags/attributes
- Lookups performed with an external data source
By doing so, you can ensure every team gets the data they need.
2. Summarize data you don’t need in full fidelity
In many instances, you don’t need to ingest complete loglines to derive value from the data. Instead, you can summarize the data upstream to support your use cases with a fraction of the total volume.
Extract metrics from your logs (“logs to metrics”)
Observability teams often need to monitor specific fields within log data over time. For example, request time or the count of 400 HTTP status codes.
In the past, teams ingested raw data in their centralized log management tool only to then create these metrics. Now, you can extract metrics upstream which reduces cost in two ways:
- Reduced data transfer costs: Metrics are a fraction the size of logs, meaning they are much less expensive to egress.
- Minimize indexing and storage costs: Since metrics are smaller, you also index and store much less data in your log management platform.
This approach means you distill your logs into the components your team needs – before you pay to index them. From there, you can route them to any metrics backend.
Deduplicate and sample loglines
Systems often generate repetitive loglines. In many cases, you need to see the total volume of logs to spot abnormal activity (e.g., errors). In others, you may only need a single logline (e.g., successful requests).
Deduplication looks for any logs that contain identical key/value data. Then it removes all but the earliest of those records, cutting bloat from your logging backend.
Similarly, sampling delivers one out of every N records of a specified data type. You keep the selected records, and discard the rest. This is an ideal way to reduce log management and SIEM costs on data where you only need a representative sample.
3. Reduce the size of log records
When your teams consume log data, only a fraction of the information may actually be useful.
For example, you might find:
- Entire fields or key-value pairs that aren’t needed
- Punctuation that inflates logs
- Redundant or unneeded tags, such as pod_id and pod_name.
Pruning this content makes your logs less verbose. In other words, you’re not dropping any loglines. Instead, you’re shrinking them to only the contents you need. At the same time, you serve the information your team needs, creating a more effective log management practice.
One more advanced strategy that can be helpful is to remove fields from your logs based on the contents of the log itself. This is helpful in scenarios where fields are useful in specific circumstances.
For example, if the JSON value for userid present, your teams may need that information. However, if the field is “null,” it will provide no value to your team. In the latter scenario, you can remove this field
4. Minimize cloud egress costs by pre-processing data locally
Cloud data transfer fees are a large part of your logging total cost of ownership (TCO).
AWS data transfer costs can land between $0.08-$0.12 per GB. Meanwhile, Azure data transfer costs are anywhere between $0.02-$0.16 per GB.
We’ve established that most large organizations generate terabytes of log data each day. They also pay an “egress tax” on outbound data transfer to their centralized log management or SIEM solutions. That’s why you should implement the strategies discussed in this article within your environment. Pushing data processing upstream enables you to reduce Azure and AWS egress costs by optimizing your data footprint within your environment.
Optimize your logging costs with Chronosphere Telemetry Pipeline
Chronosphere Telemetry Pipeline can help you easily implement these cost saving strategies across your organization at scale. It sits between your data sources and your streaming destinations, enabling you to:
- Collect data from your existing data sources
- Transform, filter, and reduce data in flight
- Route data to one more many destinations
Additionally, you can build pipelines from a single, low-code interface. This means that your developers don’t need to re-instrument logs and you no longer need to work across a disjointed toolset. Chronosphere Telemetry Pipeline uses 20x less infrastructure resources, compared to other leading pipelines, enabling further TCO reduction. If you’re interested in learning more, book a demo here.


