")




Editor’s Note: The following article is an excerpt from The Manning Book: Effective Platform Engineering, a hands-on guide for learning how to treat your internal platform like a product, grounded in a clear SDLC (Software Development Life Cycle) and shared team standards. This excerpt uses an example environment to illustrate practical guidance on acceptance criteria, automation, and proof signals. To read the full chapter, download the book.
TL;DR
- Apply software engineering rigor to platforms—focus on stability, scalability, and maintainability for lasting value .
- Use a standardized SDLC (plan, design, code, test, deploy, monitor, iterate) for all platform changes.
- Extend the SDLC with Observability-Driven Development (ODD), embedding metrics and traces to prove features work and deliver results.
- Key ODD principles: instrument telemetry, contextual tracing, actionable metrics, automated alerts, and feedback-driven improvement.
- Document team standards in a charter for smoother onboarding and consistent development practices.
Understanding the foundational concepts of software development practices is crucial for building an effective engineering platform.
This excerpt from The Manning Book: Effective Platform Engineering will explain how to apply software engineering principles to increase the stability, scalability, extensibility, and maintainability of your platform, ensuring it delivers ongoing value to your organization.
Standardize the SDLC: Treat your platform like a product
When creating our platform, we must think about it like any other software product developed within the organization.
In Chapter 1 [which can be read in its entirety by downloading the book here], we learned about using product strategy and practices to start defining our backlog. Now we need to think about the software development practices we should use for the development, build, and release cycles for the platform.
Get started
In our experience, many platform teams will start with engineers who have an operations background, because they have more infrastructure experience than most. In traditional operations roles, simply developing scripts or Infrastructure as Code (IaC) modules and executing them manually have been generally accepted ways of working.
As we move to platform engineering, we want to introduce more rigor into the SDLC process, using software engineering principles to increase the stability, scalability, extensibility, and maintainability of what is developed. Some of these practices are probably already familiar to most experienced engineers.
Development practices: Team charter and standards
Solid engineering practices help to develop and release repeatable and maintainable software. As we define those practices, it’s helpful to create a document that the whole team agrees on so that we can be confident everyone will follow the standards in the same way from the start.
This document can also be a team charter of sorts to make onboarding new team members easier in the future. There is an example of this type of document in the Chapter 2 folder of the GitHub repo for this book called “Team_Charter.md.”
The Platform SDLC: Plan → Release → Operate → Iterate
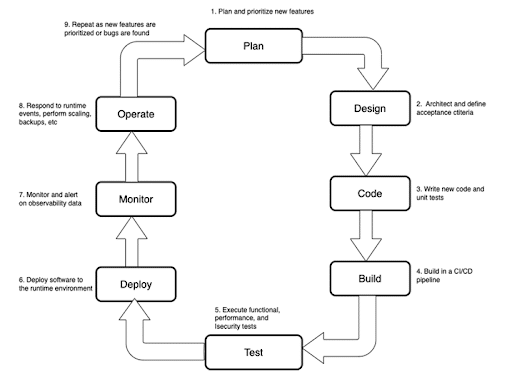
A Base Development SDLC covering all stages from feature planning through running in production. This can be used as a standard across the team to increase code quality for all releases.
Throughout this book, all code development done on an engineering platform follows the SDLC seen in the figure above. We will extend some of the sections of this as we move forward, but for now, this serves as a base SDLC process that we can document and expect the team to follow for every change made to the platform.
Platform engineering in action: Example feature planning
Plan
- Each feature will be planned to determine how it fits into the overall platform roadmap, what dependencies it may have, and how it should be prioritized.
Design
- Before beginning development, we will design the feature with architectural diagrams and acceptance criteria. This is not to say that we expect the design to be final and unchangeable. We need to keep the ability to pivot as we learn new information.
Code
- Once we have a design in place and know what the acceptance criteria are, we can start coding, including writing unit tests.
Build -> Test -> Deploy
- All deployments will go through an automated pipeline that runs tests before deployment.
Monitor
- All deployments are monitored according to requirements written during the plan phase.
Operate
- The platform team is assumed to operate autonomously, meaning that they will also support what they deploy in production.
Repeat
- Cycles can occur in any part of this process, and because we are delivering the platform as a product, it is never considered “done.” Every release informs the next release as we learn how the system is used and we fix bugs.
One thing we should note here is that to be successful, we need to have a focus on observability (monitor and operate) for the entire development lifecycle.
Observability-driven development: Extending design and code
When all tests “pass” but reality breaks
Once your engineering platform is in place and developers start using it, your team is releasing new changes regularly using all of the software practices and the full SDLC described above, and you can see that all tests are passing.
However, one engineering team reports that some of their services have intermittent communication issues. They’ve tried to diagnose the problem by looking for unhandled exceptions and HTTP error codes, and can’t find any issues in their software, so they’ve become convinced it’s a problem with the platform they can’t see and want to file a bug report.
Your team spends a couple of hours trying to track down the problem as well by looking at the metrics being produced from the runtime, and can’t find anything either, so you’re convinced it’s a problem with the other team’s software and try to work with them to find it.
Eventually, someone on the team suggests activating more granular network logs and trying to reproduce the problem once the new logging is in place. Analysis shows that a network policy in the base platform was throttling traffic because the throughput generated by the new services exceeded the threshold for a new DDoS (distributed denial-of-service) policy that was only expected to apply to external sources. A simple fix to the configuration is made and deployed, resolving the issue.
The team lost a full day of work due to the issue. They spent three hours unsuccessfully debugging, reported the bug, and waited an hour for the platform team. The platform team spent two hours checking logs and another hour debugging the new services. Once network logs were activated, it took an hour to parse them, and the fix took just 10 minutes to code and deploy.
Observability-driven Development (ODD): The fix and workflow
All of this could be mitigated with Observability-Driven Development (ODD).
ODD is a technique that guides the definition and development of new software by determining what observability data (and possibly alerting) is needed to ensure that a feature is not only working, but working correctly and delivering the intended results.
To do this, the design and code phase of the SDLC described above can be extended with a new cycle:
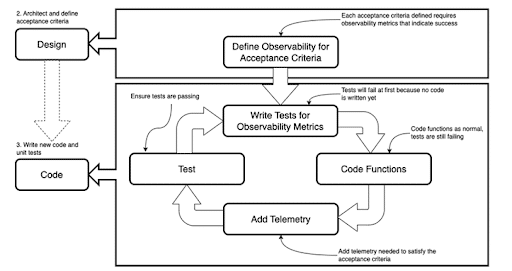
An expanded SDLC that includes ODD practices. ODD can help ensure that a delivered feature is not only working but also working correctly and returning the expected value to the organization and its customers.
Extending the Design phase: Define Observability for Acceptance Criteria
We begin by including a step in the design phase to figure out which observability data can prove that the features we release are not only functioning but also performing well and delivering the expected value.
As an example, imagine we want to add a new feature to the platform based on the scenario we went through at the beginning of this section:
- Protect the platform from external DOS attacks by throttling traffic above 1000 requests per second (RPS) to a single service from the same source.
- We need to determine what observability data we need to make sure this is working as intended by stopping traffic above the threshold. Still, we also need to think about what we need to know to determine its functioning correctly and give us the value we want (i.e., platform protection from malicious attacks).
Data to know if it’s working correctly should be pretty straightforward (you may think of other data points)
- RPS arriving at a destination address from a single source
If the feature is working as intended, this should always be at most 1000. Next, think about what data we need to show that this returns the intended value, protecting the platform from external DOS attacks.
(NOTE: Most network hardening will want to also protect against insider threats, but we won’t consider that for this example.)
To show this, we want some additional data:
- Source of the request
- Destination of the request.
- An indicator of whether this is an internal source
- How often requests are blocked from a given source
- Because this is a system security feature, alerts are defined to notify the platform team that DOS protection has been fired so that it can quickly be determined if further action needs to be taken.
ODD Development Cycle: Tests, Telemetry, and Iteration
With these data points defined, we can now begin the development cycle with the following steps:
- Tests are written to show that the observability data needed is being produced.
- Functional code is written, along with unit tests, to show the correctness.
- Logging and telemetry are added until the observability tests pass.
At a high level, the observability-driven design principles are the following.
- Instrumentation as Code: Embed telemetry (metrics, logs, traces) directly into the system, ensuring observability is integrated with the development process.
- Contextual Data and Tracing: Collect rich, contextual data and implement distributed tracing to track system behavior across services, enabling quick identification of issues in complex architectures.
- Actionable Metrics and Logs: Define key, actionable metrics, and structured logging that provide insights into system health, performance, and errors, making monitoring and troubleshooting efficient.
- Automated Alerts and Self-Service Monitoring: Enable teams to configure monitoring, dashboards, and proactive alerts, empowering quick responses to issues without centralized dependency.
- Continuous Improvement via Feedback Loops: Use observability data to focus on root causes, drive continuous system improvement, and balance innovation with reliability through error budgets.
If you know about test-driven development, this might seem familiar because it follows a similar approach.
The twist here is that we go beyond just writing tests to check if things work. We also ensure that the data itself can confirm everything is correct and that we’re actually getting the value we expect.
If we deliver this feature with the observability data we defined, and if the scenario we started with were to happen, the platform team would get an alert right away that traffic was being blocked. They could quickly see that the traffic was coming from an internal source and that something was misconfigured with the policy. It could be that the definition of internal addresses is wrong.
In addition, because the team saw intermittent network failures, and not persistent blocks, the time a detected source is blocked is likely too short. The platform team could now notify the application team that a problem with the platform was detected, and they’re working on fixing it, saving hours of effort all around.
This article excerpt established a common SDLC for software-defined platforms and introduced Observability-Driven Development, so features are provably working and delivering value. Next, we shift from foundations to evolution—backlog tactics, short feedback loops, and fitness functions that measure a platform’s usability, reliability, and changeability. To keep reading — and get the full context — download the entire book.
Frequently Asked Questions
What is a software-defined platform in platform engineering?
A software-defined platform applies software engineering principles—such as stability, scalability, extensibility, and maintainability—to internal developer platforms. Instead of relying on ad-hoc scripts or manual processes, platform teams follow a defined software development lifecycle (SDLC) to treat the platform as a product that delivers ongoing value to the organization.
Why should platform teams follow a standardized SDLC?
A standardized SDLC ensures every platform change—from planning to monitoring—follows the same process, which improves code quality, reduces deployment risks, and helps teams continuously iterate. By aligning on shared stages like planning, design, testing, deployment, and monitoring, engineering organizations create repeatable, maintainable, and consistent platform practices.
How does Observability-Driven Development (ODD) improve platform reliability?
Observability-Driven Development extends the design and coding phases of the SDLC to define what metrics, logs, and traces are needed to prove that a feature works as expected. By embedding observability into acceptance criteria, ODD ensures teams can validate that features are not only functional but also deliver their intended value. This reduces troubleshooting time and makes platform issues more transparent.
What are the key principles of Observability-Driven Development?
ODD is grounded in five main practices:
- Contextual Data and Tracing: capturing distributed service interactions.
- Actionable Metrics and Logs: focusing on insights that aid monitoring and troubleshooting.
- Automated Alerts and Self-Service Monitoring: empowering quick issue detection.
- Continuous Improvement via Feedback Loops: using data to drive reliability and innovation.
How can a team charter improve platform development?
A team charter documents agreed-upon engineering standards and workflows, ensuring every developer follows the same best practices. It serves as both a reference guide for consistent SDLC execution and a helpful onboarding resource for new team members, reducing ramp-up time and improving alignment across distributed teams.
Effective Platform Engineering
Platform engineering isn’t just technical—it unlocks team creativity and collaboration. Learn how to build powerful, sustainable, easy-to-use platforms.


